This example uses data on movies that were released in 2011. You are particularly interested in the World Gross values, which represent the gross receipts. Your potential predictors are Rotten Tomatoes Score, Audience Score, and Genre. The two score variables are continuous, but Genre is nominal. Before you attempt to reduce your model using Stepwise, you want to explore the variables of interest.
|
1.
|
|
2.
|
Select Analyze > Distribution.
|
|
3.
|
|
4.
|
Click OK.
|
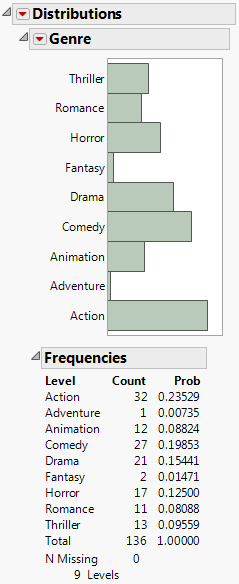
Note that Genre has nine levels, and so would be represented by eight model terms. Further data exploration will reveal that, because of missing data, only eight levels are considered by Stepwise.
|
5.
|
In the data table’s Columns panel, select the columns of interest: Rotten Tomatoes Score, Audience Score, Genre, and World Gross.
|
|
6.
|
Selects Cols > Modeling Utilities > Explore Missing Values.
|

Note that Rotten Tomatoes Score is missing in 2 rows, Audience Score is missing in 1 row, and World Gross is missing in 2 rows.
|
8.
|
Click Select Rows.
|
In the data table’s Rows panel, you can see that three rows are selected. Because these three rows contain missing data on the predictors or response, they will be automatically excluded from the Stepwise analysis. Note that row 134 is the only entry in the Adventure category, which means that category will be entirely removed from the analysis. For the purposes of the Stepwise analysis, it follows that Genre has only eight categories. Now that you have seen the effect of the missing data, you will conduct the Stepwise analysis.
|
9.
|
Select Analyze > Fit Model.
|
|
10.
|
If you fit a standard least squares model to World Gross using Rotten Tomatoes Score, Audience Score, and Genre as predictors, the residuals are highly heteroskedastic. (This is typical of financial data.) Use a log transformation to better satisfy the regression assumption of equal variance.
|
11.
|
The transformed variable Log[World Gross] appears at the bottom of the Select Columns list.
|
12.
|
|
13.
|
Select Stepwise from the Personality list.
|
|
14.
|
Click Run.
|

In the Current Estimates table, note that Genre is represented by 7 terms. You will construct a model using two of these to see how these terms are defined.
|
15.
|
|
16.
|
Click Make Model.
|
Recall that because of missing values, Genre is a nominal variable with eight levels. In the Current Estimates table, Genre is represented by seven terms. This is appropriate, because Genre has eight levels. The first two terms that represent Genre are described below. Subsequent terms are defined in a similar fashion.
The first term that appears is Genre{Drama&Thriller&Horror&Fantasy&Romance&Comedy-Action&Animation}. This variable has the form Genre{A1 - A2}, where A1 and A2 are separated by a minus sign. The notation indicates that the maximum separation in terms of sum of squares between groups occurs between the following two sets of levels:
If you include the term Genre{Drama&Thriller&Horror&Fantasy&Romance&Comedy-Action&Animation} in a model, a column representing that term is added to the data table. In the example, you saved this column to the data table. The column shows the following values:
The second term that appears is Genre{Drama-Thriller&Horror&Fantasy&Romance&Comedy}. This set of levels is entirely contained in the first split for the first term (A1). The notation contrasts the levels:
|
•
|
The splitting of terms continues, based on the sum of squares between groups criterion. The hierarchy that leads to the definition of the terms is illustrated in Tree Showing Splits Used in Hierarchical Coding.
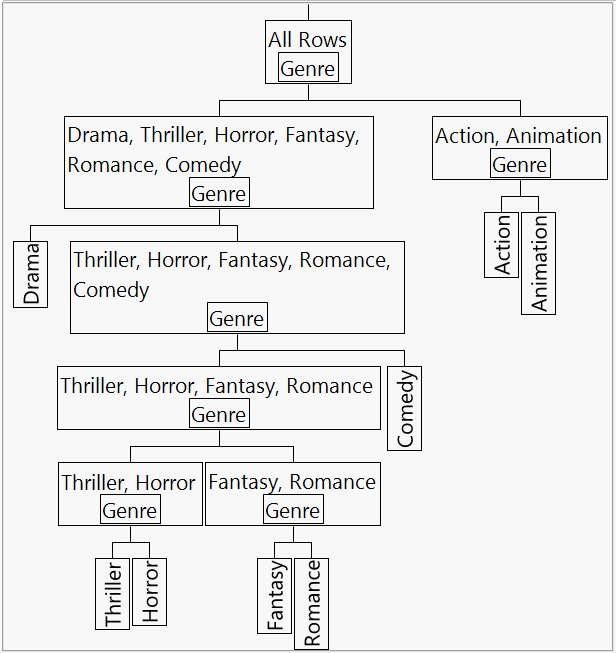
When you use the Combine rule or the Restrict rule, a term cannot enter the model unless all the terms above it in the hierarchy have been entered. For example, if you enter Genre{Action-Animation}, then JMP will enter Genre{Drama&Thriller&Horror&Fantasy&Romance&Comedy-Action&Animation} as well.
When you use the Whole Effects rule and enter any one of the Genre terms, all of the Genre terms are entered.