
Specify the number of hidden nodes of each type in each layer. For details, see Hidden Layer Structure.
 Boosting
Boosting Fitting Options
Fitting OptionsAfter you click Go to fit a model, you can reopen the Model Launch Control Panel and change the settings to fit another model.
|
•
|
The training set is the part that estimates model parameters.
|
|
•
|
The validation set is the part that estimates the optimal value of the penalty, and assesses or validates the predictive ability of the model.
|
|
•
|
The test set is a final, independent assessment of the model’s predictive ability. The test set is available only when using a validation column.
|
For more information about using row states and how to exclude rows, see Hide and Exclude Rows in the Using JMP book.
 Validation Column
Validation ColumnUses the column’s values to divide the data into parts. The column is assigned using the Validation role on the Neural launch window. See The Neural Launch Window.

where x is a linear combination of the X variables.

where x is a linear combination of the X variables.
 Boosting is the process of building a large additive neural network model by fitting a sequence of smaller models. Each of the smaller models is fit on the scaled residuals of the previous model. The models are combined to form the larger final model. The process uses validation to assess how many component models to fit, not exceeding the specified number of models.
Boosting is the process of building a large additive neural network model by fitting a sequence of smaller models. Each of the smaller models is fit on the scaled residuals of the previous model. The models are combined to form the larger final model. The process uses validation to assess how many component models to fit, not exceeding the specified number of models.The learning rate must be 0 < r ≤ 1. Learning rates close to 1 result in faster convergence on a final model, but also have a higher tendency to overfit data. Use learning rates close to 1 when a small Number of Models is specified.
 The following model fitting options are available:
The following model fitting options are available:Choose the penalty method. To mitigate the tendency neural networks have to overfit data, the fitting process incorporates a penalty on the likelihood. See Penalty Method.
The penalty is 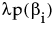 , where λ is the penalty parameter, and p( ) is a function of the parameter estimates, called the penalty function. Validation is used to find the optimal value of the penalty parameter.
, where λ is the penalty parameter, and p( ) is a function of the parameter estimates, called the penalty function. Validation is used to find the optimal value of the penalty parameter.
, where λ is the penalty parameter, and p( ) is a function of the parameter estimates, called the penalty function. Validation is used to find the optimal value of the penalty parameter.
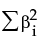 |
||
 |
||
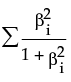 |
||