For statistical details, see Assess Variable Importance. See also Saltelli, 2002.
Factor values are constructed from observed combinations using a k-nearest neighbors approach, in order to account for correlation. This option treats observed variance and covariance as representative of the covariance structure for your factors. Use this option when you believe that your factors are correlated. Note that this option is sensitive to the number of rows in the data table. If used with a small number of rows, the results can be unreliable.
An importance index that reflects the relative contribution of that factor both alone and in combination with other factors. The Total Effect column is displayed as a bar chart. See Weights.
The Monte Carlo standard error of the Main Effect’s importance index. This is a hidden column that you can access by right-clicking in the report and selecting Columns > Main Effect Std Error. By default, sampling continues until this error is less than 0.01. Details of the calculation are given in Variable Importance Standard Errors. (Not available for Dependent Resampled Inputs option.)
The Monte Carlo standard error of the Total Effect’s importance index. This is a hidden column that you can access by right-clicking in the report and selecting Columns > Total Effect Std Error. By default, sampling continues until this error is less than 0.01. Details of the calculation are given in Variable Importance Standard Errors. (Not available for Dependent Resampled Inputs option.)
A plot that shows the Total Effect indices, located to the right of the final column. You can deselect or reselect this plot by right-clicking in the report and selecting Columns > Weights.
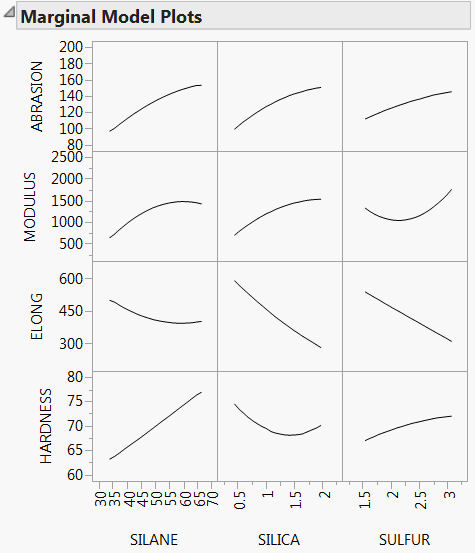
The Marginal Model Plots report (see Marginal Model Plots for Four Responses) shows a matrix of plots, with a row for each response and columns for the factors. The factors are ordered according to the size of their overall Total Effect importance indices.
The Boston Housing.jmp sample data table contains data on 13 factors that might relate to median home values. You will fit a model using a neural network. Because neural networks do not accommodate formal hypothesis tests, these tests are not available to help assess which variables are important in predicting the response. However, for this purpose, you can use the Assess Variable Importance profiler option.
Note that your results will differ from, but should resemble, those shown here. There are two sources of random variability in this example. When you fit the neural network, k-fold cross validation is used. This partitions the data into training and validation sets at random. Also, Monte Carlo sampling is used to calculate the factor importance indices.
|
1.
|
|
2.
|
Select Analyze > Modeling > Neural.
|
|
3.
|
|
5.
|
Click OK.
|
|
6.
|
In the Neural Model Launch panel, select KFold from the list under Validation Method.
|
|
7.
|
Click Go.
|
|
9.
|
From the red triangle menu next to Prediction Profiler, select Assess Variable Importance > Dependent Resampled Inputs.
|
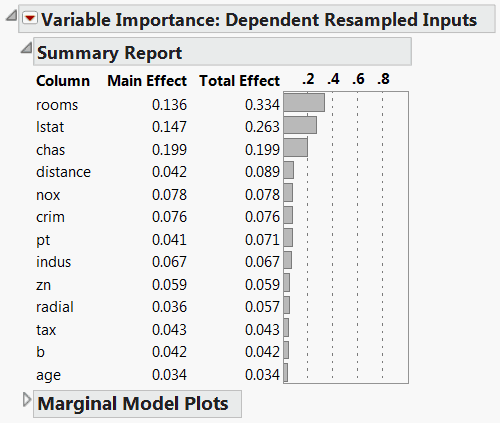
The Variable Importance: Dependent Resampled Inputs report appears (Dependent Resampled Inputs Report). Check that the Prediction Profiler cells have been reordered by the magnitude of the Total Effect indices in the report. In Dependent Resampled Inputs Report, check that the Total Effect importance indices identify rooms and lstat as the factors that have most impact on the predicted response.
|
10.
|
From the red triangle menu next to Prediction Profiler, select Assess Variable Importance > Independent Resampled Inputs.
|
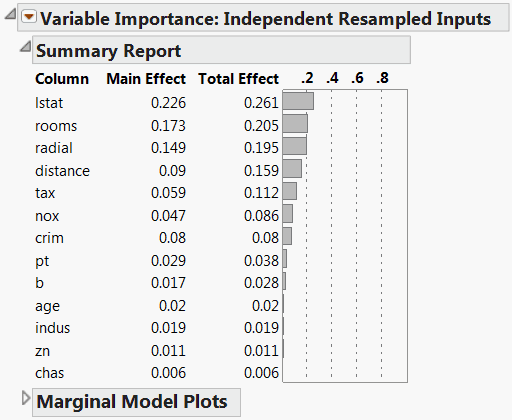
The resampled inputs option makes sense in this example, because the distributions involved are not uniform. The Variable Importance: Independent Resampled Inputs report is shown in Independent Resampled Inputs Report. Check that the two factors identified as having the most impact on the predicted values are lstat and rooms. Note that the ordering of their importance indices is reversed from the ordering using Dependent Resampled Inputs.
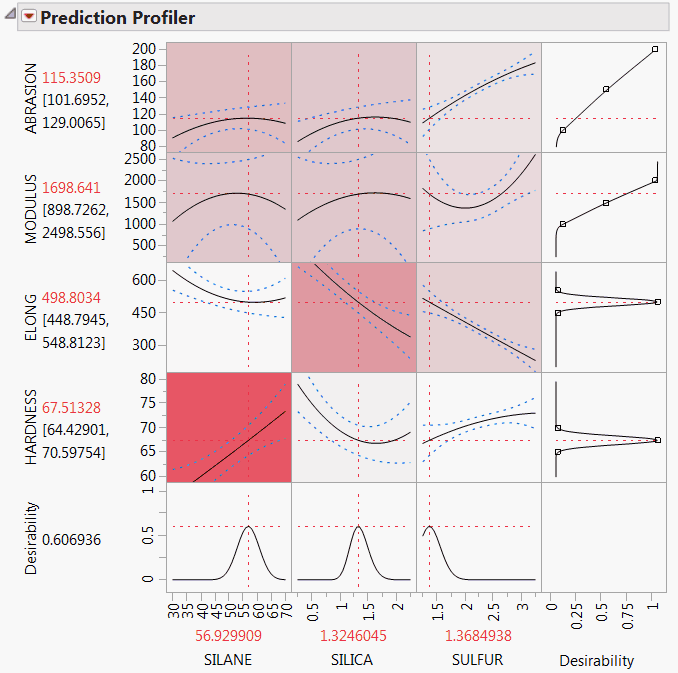
The data in the Tiretread.jmp sample data table are the result of a designed experiment where the factors are orthogonal. For this reason, you use importance estimates based on independent inputs. Suppose that you believe that, in practice, factor values vary throughout the design space, rather than assume only the settings defined in the experiment. Then you should choose Independent Uniform Inputs as the sampling scheme for your importance indices.
|
1.
|
|
2.
|
Run the script RSM for 4 Responses.
|
|
3.
|
From the red triangle menu next to Prediction Profiler, select Assess Variable Importance > Independent Uniform Inputs.
|
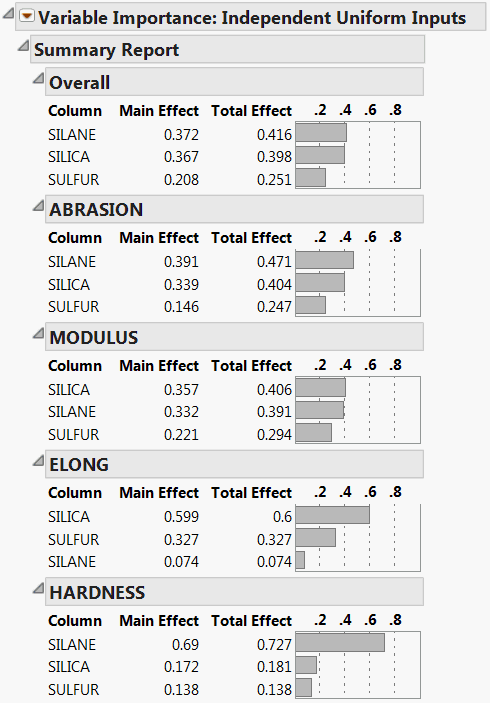
The Summary Report is shown in Summary Report for Four Responses. Because the importance indices are based on random sampling, your estimates might differ slightly from those shown in the figure.
The report shows tables for each of the four responses. The Overall table averages the factor importance indices across responses. The factors in the Profiler (Profiler for Four Responses) have been reordered to match their ordering on the Overall table’s Total Effect importance.
|
4.
|
Colors from a red to white intensity scale are overlaid on profiler panels to reflect Total Effect importance. For example, you easily see that the most important effect is that of Silane on Hardness.
The Marginal Model Plots report (Marginal Model Plots for Four Responses) shows mean responses for each factor across a uniform distribution of settings for the other two factors.