To fit models using the mixed model personality, select Analyze > Fit Model and then select Mixed Model from the Personality list. Note that when you enter a continuous variable in the Y list before selecting a Personality, the Personality defaults to Standard Least Squares.
When fitting models using the Mixed Model personality, you can allow unbounded variance components. This means that variance components that have negative estimates are not reported as zero. This option is selected by default. It should remain selected if you are interested in fixed effects, because bounding the variance estimates at zero leads to bias in the tests for fixed effects. See Negative Variances in Standard Least Squares Report and Options for details about on the Unbounded Variance Components option.
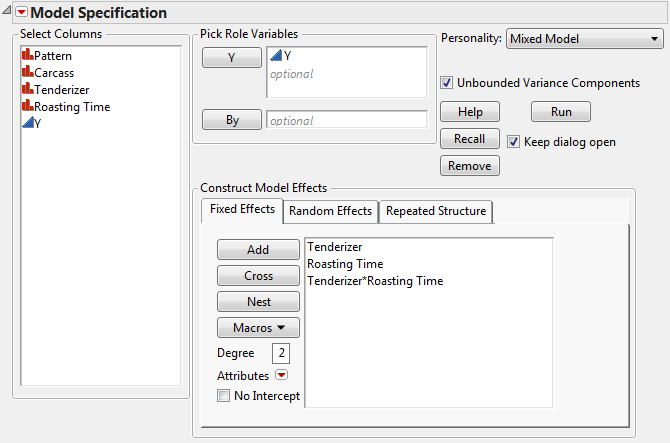
Add all fixed effects on the Fixed Effects tab. Use the Add, Cross, Nest, Macros, and Attributes options as needed. For details about using these options, see the Model Specification section.
The fixed effects for analysis of the Split Plot.jmp sample data table appear in Fit Model Launch Window Showing Completed Fixed Effects. Note that it is possible to have no fixed effects in the model.For an example, see Spatial Example: Uniformity Trial.
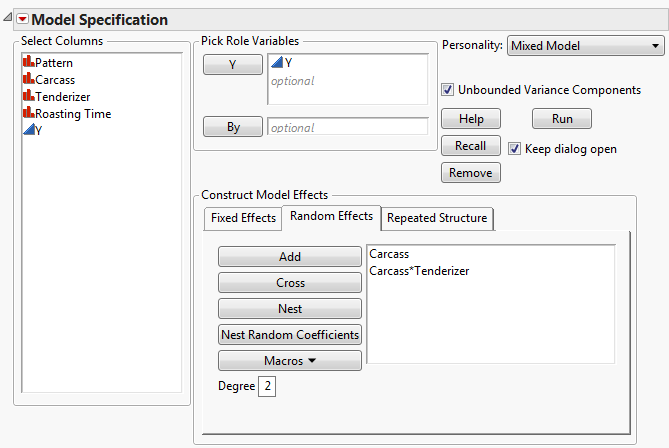
For a traditional variance component model, specify terms such as random blocks, whole plot error terms, and subplot error terms using the Add, Cross, or Nest options. For details about using these options, see the Model Specification section.
Fit Model Launch Window Showing Completed Random Effects Tab shows the random effects specification for the Split Plot.jmp sample data where Carcass is a random block. Split Plot Example describes the example in detail.
|
2.
|
|
4.
|
Click the Nest Random Coefficients button.
|
This last step creates random intercept and random slope effects that are correlated within the levels of the random effect. The subject is nested within the other effects due to the variability among subjects. If you believed that the intercept might be fixed for all groups, you would select Intercept[<group>]&Random Coefficients(1) and then click Remove.
Random coefficients are modeled using an unstructured covariance structure. Completed Fit Model Launch Window Showing Random Coefficients shows the random coefficients specification for the Wheat.jmp sample data. (See also Example Using Mixed Model.)

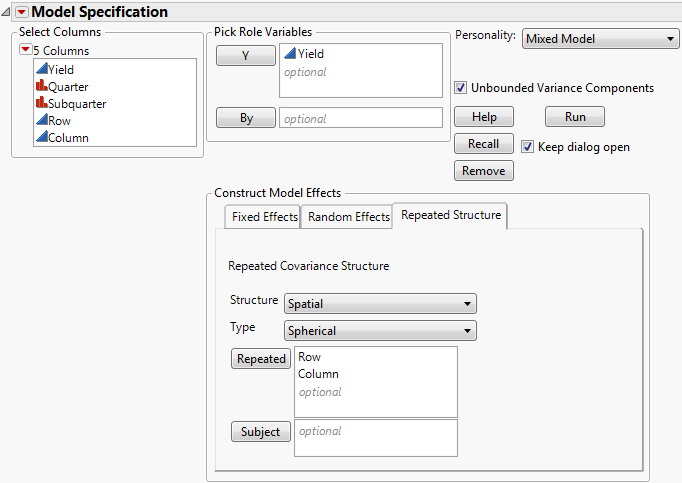
The repeated structure is set to Residual by default. The Residual structure specifies that there is no covariance between observations, namely, the errors are independent. All other covariance structures model covariance between observations. For details about the structures, see Repeated Measures and Spatial and Temporal Variability in the “Statistical Details” section.
Repeated Covariance Structure Requirements lists the covariance structures available and the requirements for using each structure.
When you select one of the spatial covariance structures, a Type list appears from which you select a type of spatial structure. Four Types are available: Power, Exponential, Gaussian, and Spherical. Completed Fit Model Launch Window Showing Repeated Structure Tab shows the Spatial Spherical selection for the Uniformity Trial.jmp sample data.