在选择“按对象保存梯度”选项后,您所获得的梯度值是优化过程中用于生成估计值的按测试对象聚合的 Newton-Raphson 步长。在估计中,总梯度为零,Δ = H-1g = 0,其中 g 是最大似然估计中的对数似然函数的总梯度,H-1 是 Hessian 函数的反函数或对数似然函数的二阶偏导数负数的反函数。
但是,取消聚合 Δ 将生成以下结果:
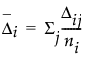 ,
,其中 ni 是每个测试对象的试验次数。这些 Δi 与测试对象 i 对最终参数估计的影响力度有关。若各组测试对象确实有不同的偏好结构,其对参数估计能够产生较强的影响力度,因此可用于对测试对象聚类。Δi 即为保存的梯度力。接下来您便可以使用“聚类”平台对这些值进行聚类。