使用 Reactor Half Fraction.jmp 样本数据表。该数据源自 Box, Hunter, and Hunter (1978) 中讨论的设计。您关注的是包含主效应和双因子交互作用的模型。该示例针对包含 16 次试验的设计使用一个包含 15 个参数的模型。
对于本例,将所有连续因子(响应反应百分比除外)选作筛选效应 X。将反应百分比选作响应 Y。“筛选”平台自动构造交互作用。这与“拟合模型”形成对比,您需要在“拟合模型”中手动指定要包括在模型中的交互作用。
传统饱和的 Half Reactor.jmp 设计输出
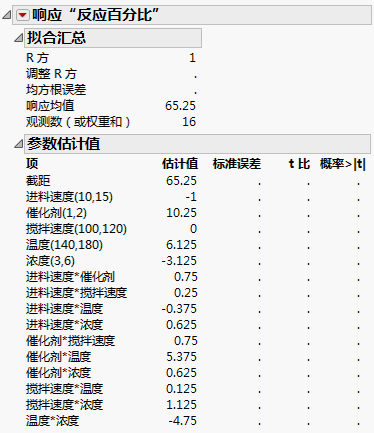
JMP 可计算参数估计值,但因为误差没有自由度,标准误差、t 比和 p 值全部缺失。与使用“拟合模型”相比,使用“拟合两水平筛选”平台可以构建更好的模型,因为该平台非常善于从以上情形中获取最多信息。“拟合两水平筛选”平台为同一数据生成的报表显示在Half Reactor.jmp“拟合两水平筛选设计”报表中。
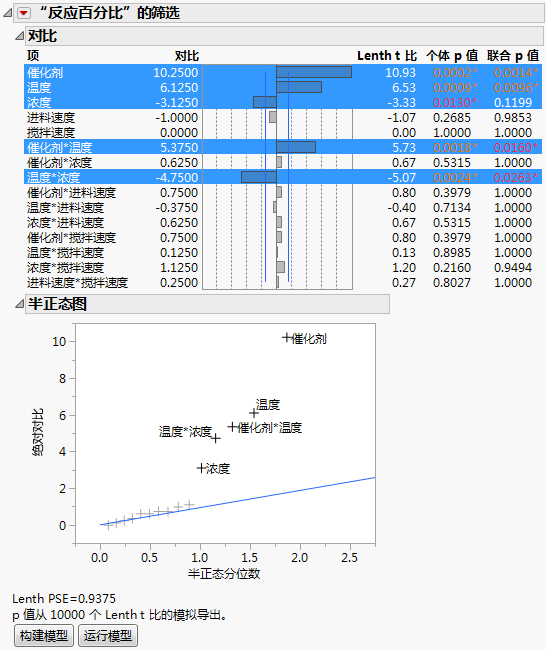
Half Reactor.jmp“拟合两水平筛选设计”报表
|
•
|
|
•
|
t 比使用 Lenth PSE(伪标准误差)计算。Lenth PSE 显示在“半正态图”下方。
|
|
•
|
同时显示个体和联合 p 值。小于 0.05 的 p 值标有星号。
|
|
•
|