仅当在“模型启动”控制面板中将某种交叉验证方式选为“验证方法”时,才显示该报表。它显示模型拟合的汇总统计量,拟合所用的因子数为 0 到提取的最大因子数(在“模型启动”控制面板中指定)。该报表还提供“PRESS 均值根值图”。请参见PRESS 均值根图。 使用最小 PRESS 均值根统计量标识最佳因子数。
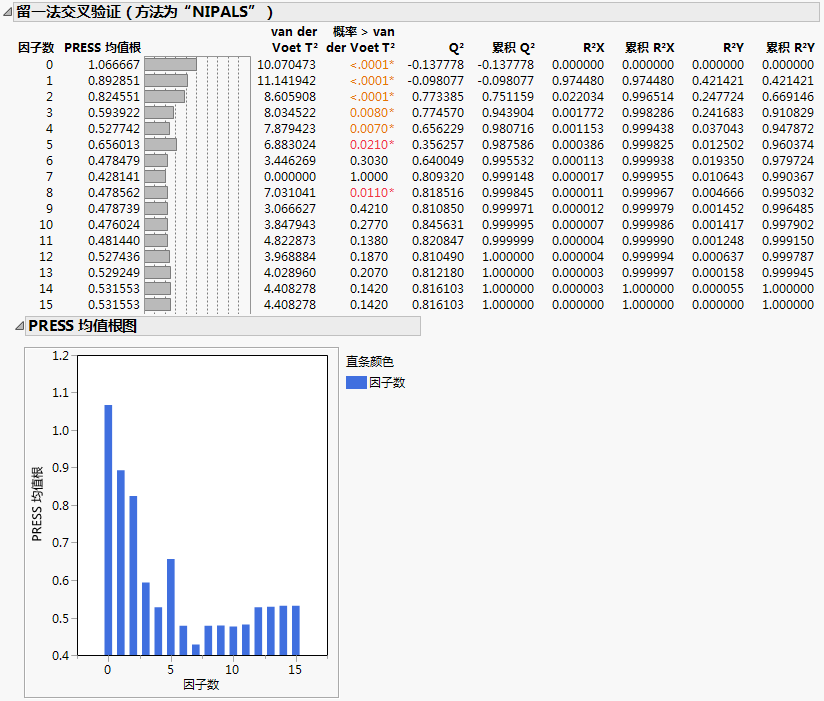
van der Voet 检验的统计量,它检验具有不同提取因子数的模型是否与最佳模型存在显著差异。每个 van der Voet T2 检验的原假设假定基于相应因子数的模型与最佳模型没有差异。备择假设是该模型与最佳模型有差异。有关更多详细信息,请参见van der Voet T2。
Q2
累积 Q2
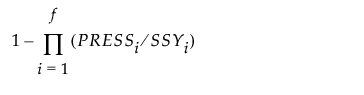
R2X
累积 R2X
R2Y
累积 R2Y
|
•
|
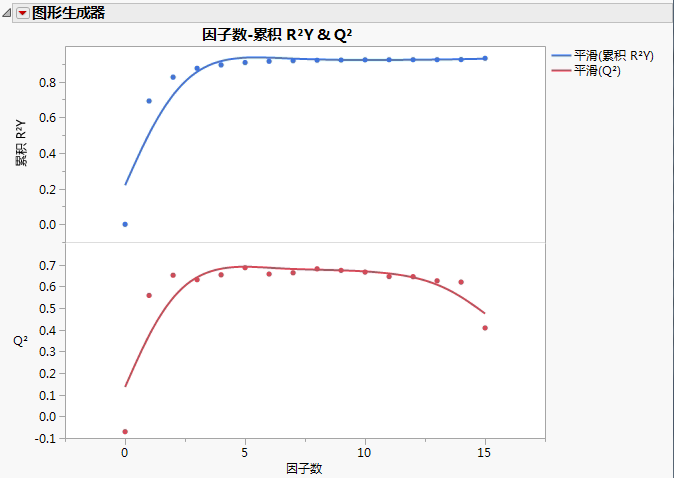
累积 R2Y 随因子数的增加而增大。这是因为随着因子添加至模型,更多的变异得到解释。
|
|
•
|
Q2 的趋势是随因子数的增加,先增大后减小(或至少停止增大)。这是因为随着更多的因子添加至模型,模型开始调整训练集,不能很好地推广到新数据,导致 PRESS 统计量减小。
|
Penta.jmp 的累积 R2Y 和 Q2显示 Penta.jmp 数据表针对因子数标绘的累积 R2Y 和 Q2,验证方法为“留一法”。累积 R2Y 增加,并且在大约四个因子时开始趋于平稳。统计量 Q2 在两个因子时最大,然后开始趋于平稳。该图表明具有两个因子的模型将能够解释 Y 中的大部分变异,且不会过拟合数据。
对于指定的因子数 a,按以下方式计算“PRESS 均值根”:
|
1.
|
对每个训练集拟合具有 a 个因子的模型。
|
|
3.
|
|
4.
|
a 个因子的“PRESS 均值根”是所有响应的 PRESS 值的平均值的平方根。
|
|
5.
|
多个 Y 的 PRESS 统计量通过计算在步骤 3中获得的全部响应的 PRESS 统计量的平均值得到。
|
统计量 Q2 定义为 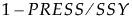 。PRESS 统计量是模型的所有响应的预测误差平方和平均值,该模型基于训练集构建,但是基于验证集计算。SSY 的值是所有响应的 Y 的平方和平均值,这些响应基于验证集中的观测值。
。PRESS 统计量是模型的所有响应的预测误差平方和平均值,该模型基于训练集构建,但是基于验证集计算。SSY 的值是所有响应的 Y 的平方和平均值,这些响应基于验证集中的观测值。