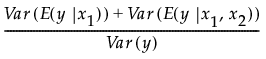|
•
|
|
•
|
主效应 xj 对 y 的影响可通过 Var(E(y |xj)) 来描述。此处期望值是 x1, x2, ..., xn 的条件分布下给定 xj 时的取值,而方差是在 xj 分布下的取值。换言之,Var(E(y |xj)) 在xj 分布下测量当xj 固定时y 均值中的变异。
“总效应”列表示涉及 xj 的所有项对 y = f(x1, x2 ..., xn) 方差的总贡献。“主效应”的计算取决于函数分解的概念。函数 f 分解为一个常数与各函数(表示单个变量、成对变量等的效应)之和。这些构成函数类似于主效应、交互作用效应和高阶效应。(请参见 Saltelli,2002 和 Sobol,1993。)
这些具有包含 xj 的项的构成函数将被标识出来。对于以上每个函数,都会计算条件预期值的方差。这些方差将被求和。总和表示因包含 xj 的项而对 Var(y) 的总贡献。对于每个 xj,将使用用于生成输入的选定方法估计该总和。“总效应”列中报告的重要性指标即这些估计值(请参见抽样变异的调整)。