|
•
|
|
•
|
|
•
|
|
•
|
|
•
|

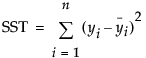
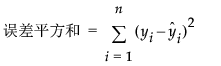
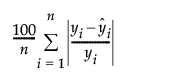
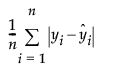
指示移动平均算子是否可逆。即是否 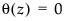 的所有根位于单位圆之外。
的所有根位于单位圆之外。
假设每个参数为零的检验统计量。参数的检验统计量是参数估计值与标准误差的比。若假设为真,则该统计量近似服从 Student t 分布。根据一般规则,通常查找绝对值大于 2 的 t 比来判断显著性,因为它近似于 0.05 显著性水平。
控制为模型显示哪些残差统计量。这些显示内容在“时间序列”平台选项一节中介绍。但是,它们应用到残差序列。