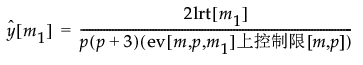|
•
|
|
•
|
|
‒
|
|
‒
|
|
‒
|
似然比检验方法用于确定均值向量和协方差矩阵中的一个还是两者均发生变化。使用似然比检验统计量来计算近似上控制限为 1 的控制图统计量。为所有可能的 m1 值标绘该控制图统计量。若任何观测的控制图统计量超过上控制限 1,这表示发生了偏移。假定正好有一个偏移,该偏移被视为紧跟在具有最大控制图统计量值的观测之后。
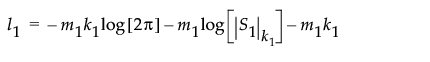
l1 的等式使用以下符号:
|
•
|
|
•
|
|
•
|
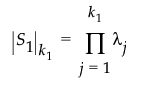
似然比检验统计量将 l1 + l2 的和与 l0 进行比较。l1 + l2 的和是该对数似然的两倍,后者假定 m1 处可能有偏移。值 l0 是假定无偏移的对数似然的两倍。若 l0 远小于 l1 + l2,则假定过程是不稳定的。
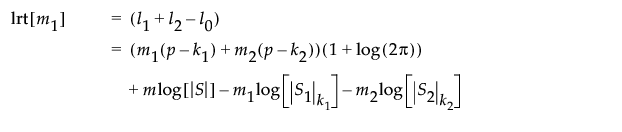
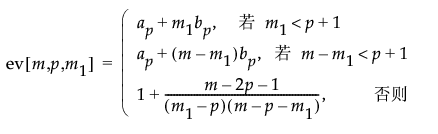
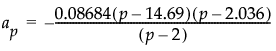
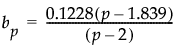
将控制图统计量定义为似然比检验统计量对数的两倍除以 p(p + 3)、除以其近似期望值以及控制限的近似值。因为除以上控制限的近似值,因此可以针对上控制限 1 标绘控制图统计量。按以下方式给出近似控制图统计量: