ANOVA univariée
Qu'est-ce l'ANOVA univariée ?
L'analyse de la variance (ANOVA) univariée est une méthode statistique permettant de comparer des moyennes de trois groupes ou plus.
Comment utilise-t-on l'ANOVA univariée ?
L'ANOVA univariée est généralement utilisée lorsque l'on a une seule variable indépendante, ou facteur, et que l'objectif est de vérifier si des variations, ou des niveaux différents de ce facteur ont un effet mesurable sur une variable dépendante.
Quelles sont les limites à prendre en compte ?
L'ANOVA univariée ne s'utilise que lorsque l'on étudie un seul facteur et une seule variable dépendante. Pour comparer les moyennes de trois groupes ou plus, elle indique si au moins une paire de moyennes est significativement différente, mais elle n'indique pas laquelle. En outre, elle requiert que la variable dépendante soit normalement répartie dans chacun des groupes et que la variabilité au sein des groupes soit similaire entre les groupes.
L'ANOVA univariée compare les moyennes de groupe
L'ANOVA univariée est une méthode statistique visant à tester l'hypothèse nulle (H0) selon laquelle les moyennes de trois ou quatre populations sont égales, comparée à l'hypothèse alternative(Ha) selon laquelle au moins une moyenne est différente. Selon la notation officielle des hypothèses statistiques, pour k moyennes on écrit :
$ H_0:\mu_1=\mu_2=\cdots=\mu_k $
$ H_a:\mathrm{not\mathrm{\ }toutes\ les moyennes\ sont\ égales} $
où $\mu_i$ est la moyenne du i-ème niveau du facteur.
Vous allez peut-être vous demander dans quelles situations vous pourriez avoir besoin de savoir si les moyennes de plusieurs populations sont identiques ou différentes ? Prenons un scénario simple : vous soupçonnez qu'une variable de processus indépendante particulière soit un facteur d'un résultat important de ce processus. Par exemple, vous pensez que des lots de production, des opérateurs ou des lots de matières premières différents affectent l'issue (que l'on appelle également mesure de la qualité) d'un processus de production.
Pour tester votre hypothèse, vous pourriez exécuter le processus en utilisant trois variations ou plus (les niveaux) de cette variable indépendante (le facteur), puis prendre un échantillon d'observations émanant des résultats de chaque exécution. Si la comparaison des moyennes de chaque groupe d'observations à l'aide d'une ANOVA révèle des différences, alors (à supposer que vous avez tout fait correctement ) vous avez montré que vous aviez raison ; le facteur que vous avez étudié semble jouer un rôle dans le résultat !
Un exemple d'ANOVA univariée
Analysons un exemple d'ANOVA univariée plus en détail. Imaginez que vous travaillez pour une société qui fabrique un gel adhésif vendu dans des petits pots. La viscosité du gel est importante : trop épais, il est difficile à appliquer, trop liquide, il ne colle pas. Récemment, vous avez reçu des plaintes de quelques clients mécontents indiquant que la viscosité de votre adhésif n'est pas la même que d'habitude. Votre supérieur vous a demandé d'enquêter.
En premier lieu, vous décidez d'examiner la viscosité moyenne des cinq derniers lots de production. Si vous trouvez des différences entre les lots, cela pourrait confirmer qu'il y a effectivement un problème. Cela pourrait également vous permettre de formuler des hypothèses concernant les facteurs potentiellement responsables des différences entre les lots.
Vous mesurez la viscosité à l'aide d'un instrument qui fait tourner une tige immergée dans le pot d'adhésif. Ce test donne une mesure appelée résistance au couple. Vous testez cinq pots sélectionnés aléatoirement dans chacun des cinq derniers lots. Vous obtenez la mesure de la résistance au couple pour chaque pot et tracer un graphique.
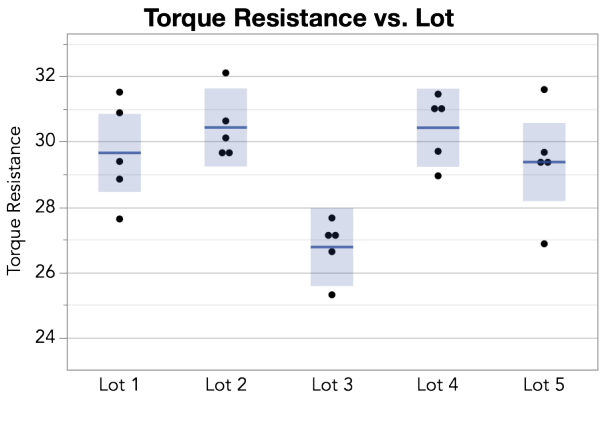
À partir de cette courbe, vous observez que les mesures de couple issues des pots du Lot 3 tendent à être inférieures à celles issues des échantillons des autres lots. Lorsque vous calculez les moyennes de toutes vos mesures, vous vous apercevez que le couple moyen du Lot 3 est de 26,77, ce qui est bien inférieur aux quatre autre lots, chacune ayant une moyenne d'environ 30.
Tableau 1 : mesures de couple moyen issues des tests de cinq lots d'adhésif
| N° de lot | Nombre d'observations | Moyenne |
|---|---|---|
| 1 | 5 | 29,65 |
| 2 | 5 | 30,43 |
| 3 | 5 | 26,77 |
| 4 | 5 | 30,42 |
| 5 | 5 | 29,37 |
Tableau ANOVA
Les résultats ANOVA sont généralement affichés dans un tableau ANOVA. Un tableau ANOVA inclut :
- Source : les sources de variation incluant le facteur à l'étude (dans notre cas, le lot), l'erreur et le total.
- DF (degrees of freedom) : degrés de liberté pour chaque source de variation.
- Sum of Squares (SS) : la somme des carrés de chaque source de variation ainsi que le total de toutes les sources.
- Mean Square (carré moyen) : somme des carrés divisée par son degrés de liberté.
- F Ratio (rapport F) : le carré moyen du facteur (lot) divisé par le carré moyen de l'erreur.
- Prob > F : la valeur p.
Tableau 2 : tableau ANOVA avec résultats de nos mesures de couple
| Source | Degrés de liberté | Somme des carrés | Carré moyen | Rapport F | Prob. > F |
|---|---|---|---|---|---|
| Lot | 4 | 45,25 | 11,31 | 6,90 | 0,0012 |
| Erreur | 20 | 32,80 | 1,64 | ||
| Total | 24 | 78,05 |
Nous allons expliquer comment on déduit les composantes de ce tableau. La valeur p est un élément clé de ce tableau sur lequel on se concentre pour l'instant. La valeur p sert à évaluer la validité de l'hypothèse nulle selon laquelle les moyennes sont identiques. Dans notre exemple, la valeur p (Prob > F) est 0,0012. Cette faible valeur p peut prouver que les moyennes ne sont pas toutes identiques. Nos échantillons prouvent qu'il existe une différence entre les valeurs moyennes de résistance au couple d'un ou plusieurs des cinq lots.
Qu'est-ce que la valeur p ?
La valeur p est une mesure de la probabilité utilisée pour tester l'hypothèse. Le but du test d'hypothèse est de déterminer s'il existe suffisamment de preuves pour soutenir une certaine hypothèse concernant vos données. N'oubliez pas qu'avec l'ANOVA, on formule deux hypothèses : l'hypothèse nulle selon laquelle toutes les moyennes sont égales et l'hypothèse alternative selon laquelle toutes les moyennes ne sont pas égales.
Étant donné que l'on examine uniquement des échantillons aléatoires de données issues de populations entières, il est possible que les moyennes de nos échantillons ne soient pas représentatives des moyennes des populations entières. La valeur p nous donne un moyen de quantifier ce risque. Il s'agit de la probabilité qu'une variabilité des moyennes de vos données d'échantillon soit le pur fruit du hasard ; plus précisément, il s'agit de la probabilité d'observer des variances dans les moyennes d'échantillon au moins aussi importantes que ce que vous avez mesuré lorsqu'en fait l'hypothèse nulle est vraie (les moyennes de la population entière sont, en fait, égales).
Une faible valeur p impliquerait de rejeter l'hypothèse nulle. En général, le seuil de rejet d'une hypothèse nulle est de 0,05. Ainsi, si vous avez une valeur p inférieure à 0,05, vous rejetez l'hypothèse nulle en faveur de l'hypothèse alternative selon laquelle au moins une moyenne est différente des autres.
D'après ces résultats, vous décidez de garder le Lot 3 pour approfondir les tests. Dans votre rapport, vous pourriez écrire : le couple des cinq pots de produit a été mesuré dans chacun des cinq derniers lots de production. Une analyse de l'ANOVA a montré que les observations soutiennent une différence de couple moyen entre les lots (p = 0,0012). Une courbe des données indiquent que le Lot 3 présentait un couple moyen inférieur (26,77) par rapport aux quatre autres lots. Nous allons garder le Lot 3 pour évaluation approfondie.
N'oubliez pas, une analyse de l'ANOVA ne vous indiquera pas quelle(s) moyenne(s) diffère(nt) des autres, et (contrairement à notre exemple) cela ne se voit pas toujours à partir d'une courbe des données. Pour répondre aux questions concernant des types spécifiques de différences, on peut utiliser un test de comparaison multiple. Par exemple, pour comparer les moyennes de groupe à la moyenne globale, on peut utiliser l'analyse des moyennes (ANOM). Pour comparer des paires individuelles de moyennes, on peut utiliser le test de comparaison multiple de Tukey-Kramer.
Calcul de l'ANOVA univariée
À présent, étudions notre exemple de mesure du couple plus en détail. Souvenez-vous que nous avions cinq lots de produits. Dans chaque lot, nous avons sélectionné aléatoirement cinq pots pour analyse. C'est ce que l'on appelle un plan à un facteur. Le facteur (lot) possède cinq niveaux. Chaque niveau est répliqué (testé) cinq fois. Les résultats du test sont fournis ci-dessous.
Tableau 3 : mesures de couple par lot
| Lot 1 | Lot 2 | Lot 3 | Lot 4 | Lot 5 | |
|---|---|---|---|---|---|
| Pot 1 | 29,39 | 30,63 | 27,16 | 31,03 | 29,67 |
| Pot 2 | 31,51 | 32,10 | 26,63 | 30,98 | 29,32 |
| Pot 3 | 30,88 | 30,11 | 25,31 | 28,95 | 26,87 |
| Pot 4 | 27,63 | 29,63 | 27,66 | 31,45 | 31,59 |
| Pot 5 | 28,85 | 29,68 | 27,10 | 29,70 | 29,41 |
| Moyenne | 29,65 | 30,43 | 26,77 | 30,42 | 29,37 |
Afin d'explorer les calculs à l'origine du tableau ANOVA ci-dessus (Tableau 2), commençons par établir les définitions suivantes :
$n_i$ = Nombre d'observations à traiter $i$ (dans notre exemple, Lot $i$)
$N$ = Nombre total d'observations
$Y_{ij}$ = La jème observation sur le ième traitement
$\overline{Y}_i$ = la moyenne de l'échantillon pour le ième traitement
$\overline{\overline{Y}}$ = la moyenne de toutes les observations (moyenne globale)
Somme des carrés
À l'aide de ces définitions, occupons-nous de la colonne Somme des carrés du tableau ANOVA. La somme des carrés nous permet de quantifier la variabilité dans un ensemble de données en ciblant la différence entre chaque point de données et la moyenne de tous les points des données dans cet ensemble de données. La formule ci-dessous sépare la variabilité globale en deux parties : la variabilité due au modèle ou aux niveaux de facteur, et la variabilité due à l'erreur aléatoire.
$$ \sum_{i=1}^{a}\sum_{j=1}^{n_i}(Y_{ij}-\overline{\overline{Y}})^2\;=\;\sum_{i=1}^{a}n_i(\overline{Y}_i-\overline{\overline{Y}})^2+\sum_{i=1}^{a}\sum_{j=1}^{n_i}(Y_{ij}-\overline{Y}_i)^2 $$
$$ SS(Total)\; = \;SS(Facteur)\; + \;SS(Erreur) $$
Bien que cette équation puisse sembler compliquée, prendre chaque élément séparément facilite grandement la tâche. Le Tableau 4 ci-dessous liste chaque composante de la formule et les compile dans les termes au carré qui constituent la somme des carrés. La première colonne de données ($Y_{ij}$) contient les mesures de couple que nous avons rassemblées dans le Tableau 3 ci-dessus.
Autre manière d'analyser les sources de variabilité : variation entre groupes et variation au sein du groupe
N'oubliez pas que dans notre tableau ANOVA ci-dessus (Tableau 2), la colonne Source liste deux sources de variation : facteur (dans notre exemple, le lot) et erreur. Ces deux sources peuvent également être analysées selon la variation entre groupes (ce qui correspond à la variation due au facteur ou au traitement) et la variation au sein du groupe (ce qui correspond à la variation due au hasard ou à l'erreur). Ainsi, grâce à cette terminologie, notre formule de la somme des carrés calcule en fait la somme de la variation due aux différences entre les groupes (l'effet de traitement) et la variation due aux différences au sein de chaque groupe (différences inexpliquées dues au hasard).
Tableau 4 : calcul de la somme des carrés
| Lot | $Y_{ij} $ | $\overline{Y}_i $ | $\overline{\overline{Y}}$ | $\overline{Y}_i-\overline{\overline{Y}}$ | $Y_{ij}-\overline{\overline{Y}}$ | $Y_{ij}-\overline{Y}_i $ | $(\overline{Y}_i-\overline{\overline{Y}})^2 $ | $(Y_{ij}-\overline{Y}_i)^2 $ | $(Y_{ij}-\overline{\overline{Y}})^2 $ |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 29,39 | 29,65 | 29,33 | 0,32 | 0,06 | -0,26 | 0,10 | 0,07 | 0,00 |
| 1 | 31,51 | 29,65 | 29,33 | 0,32 | 2,18 | 1,86 | 0,10 | 3,46 | 4,75 |
| 1 | 30,88 | 29,65 | 29,33 | 0,32 | 1,55 | 1,23 | 0,10 | 1,51 | 2,40 |
| 1 | 27,63 | 29,65 | 29,33 | 0,32 | -1,70 | -2,02 | 0,10 | 4,08 | 2,89 |
| 1 | 28,85 | 29,65 | 29,33 | 0,32 | -0,48 | -0,80 | 0,10 | 0,64 | 0,23 |
| 2 | 30,63 | 30,43 | 29,33 | 1,10 | 1,30 | 0,20 | 1,21 | 0,04 | 1,69 |
| 2 | 32,10 | 30,43 | 29,33 | 1,10 | 2,77 | 1,67 | 1,21 | 2,79 | 7,68 |
| 2 | 30,11 | 30,43 | 29,33 | 1,10 | 0,78 | -0,32 | 1,21 | 0,10 | 0,61 |
| 2 | 29,63 | 30,43 | 29,33 | 1,10 | 0,30 | -0,80 | 1,21 | 0,64 | 0,09 |
| 2 | 29,68 | 30,43 | 29,33 | 1,10 | 0,35 | -0,75 | 1,21 | 0,56 | 0,12 |
| 3 | 27,16 | 26,77 | 29,33 | -2,56 | -2,17 | 0,39 | 6,55 | 0,15 | 4,71 |
| 3 | 26,63 | 26,77 | 29,33 | -2,56 | -2,70 | -0,14 | 6,55 | 0,02 | 7,29 |
| 3 | 25,31 | 26,77 | 29,33 | -2,56 | -4,02 | -1,46 | 6,55 | 2,14 | 16,16 |
| 3 | 27,66 | 26,77 | 29,33 | -2,56 | -1,67 | 0,89 | 6,55 | 0,79 | 2,79 |
| 3 | 27,10 | 26,77 | 29,33 | -2,56 | -2,23 | 0,33 | 6,55 | 0,11 | 4,97 |
| 4 | 31,03 | 30,42 | 29,33 | 1,09 | 1,70 | 0,61 | 1,19 | 0,37 | 2,89 |
| 4 | 30,98 | 30,42 | 29,33 | 1,09 | 1,65 | 0,56 | 1,19 | 0,31 | 2,72 |
| 4 | 28,95 | 30,42 | 29,33 | 1,09 | -0,38 | -1,47 | 1,19 | 2,16 | 0,14 |
| 4 | 31,45 | 30,42 | 29,33 | 1,09 | 2,12 | 1,03 | 1,19 | 1,06 | 4,49 |
| 4 | 29,70 | 30,42 | 29,33 | 1,09 | 0,37 | -0,72 | 1,19 | 0,52 | 0,14 |
| 5 | 29,67 | 29,37 | 29,33 | 0,04 | 0,34 | 0,30 | 0,00 | 0,09 | 0,12 |
| 5 | 29,32 | 29,37 | 29,33 | 0,04 | -0,01 | -0,05 | 0,00 | 0,00 | 0,00 |
| 5 | 26,87 | 29,37 | 29,33 | 0,04 | -2,46 | -2,50 | 0,00 | 6,26 | 6,05 |
| 5 | 31,59 | 29,37 | 29,33 | 0,04 | 2,26 | 2,22 | 0,00 | 4,93 | 5,11 |
| 5 | 29,41 | 29,37 | 29,33 | 0,04 | 0,08 | 0,04 | 0,00 | 0,00 | 0,01 |
| Somme des carrés | SS (Facteur) = 45,25 | SS (Erreur) = 32,80 | SS (Total) = 78,05 |
Degrés de liberté (DF)
Une quantité appelée degrés de liberté (DF) est associée à chaque somme des carrés. Les degrés de liberté indiquent le nombre d'informations indépendantes utilisées pour calculer chaque somme des carrés. Pour un plan à un facteur avec un facteur à k niveaux (cinq lots dans notre exemple) et un total de N observations (cinq pots par lot pour un total de 25), les degrés de libertés sont les suivants :
Tableau 5 : déterminer les degrés de liberté
| Formule des degrés de liberté (DF) | Degrés de liberté calculés | |
|---|---|---|
| SS (Facteur) | k - 1 | 5 - 1 = 4 |
| SS (Erreur) | N - k | 25 - 5 = 20 |
| SS (Total) | N - 1 | 25 - 1 = 24 |
Carrés moyens (MS) et rapport F
On divise chaque somme des carrés par les degrés de liberté correspondant pour obtenir des carrés moyens. Lorsque l'hypothèse nulle est vraie (les moyennes sont égales), le MS (Facteur) et MS (Erreur) sont deux estimations de la variance de l'erreur et doivent être du même ordre. Leur rapport, le rapport F, doit être proche de 1. Lorsque l'hypothèse nulle n'est pas vraie, le MS (Facteur) est supérieur au MS (Erreur) et leur rapport est supérieur à 1. Dans notre exemple des adhésifs, le rapport F calculé, 6,90, présente des preuves significatives contre l'hypothèse nulle selon laquelle les moyennes sont égales.
Tableau 6 : calculer les carrés moyens et le rapport F
| Somme des carrés (SS) | Degrés de liberté (DF) | Carrés moyens | Rapport F | |
|---|---|---|---|---|
| SS (Facteur) | 45,25 | 4 | 45,25/4 = 11,31 | 11,31/1,64 = 6,90 |
| SS (Erreur) | 32,80 | 20 | 32,80/20 = 1,64 |
Le rapport de MS(facteur) sur MS(erreur), le rapport F, a une distribution F. La distribution F est la distribution des valeurs F que nous pensons observer lorsque l'hypothèse nulle est vraie (c'est-à-dire lorsque les moyennes sont égales). Les valeurs de distribution F prennent différentes formes en fonction de deux paramètres que l'on appelle degrés de liberté du numérateur et du dénominateur. Pour une analyse ANOVA, le numérateur est le MS(facteur), les degrés de liberté du numérateur sont donc ceux associés au MS(facteur). Le dénominateur est le MS(erreur), les degrés de liberté du dénominateur sont donc ceux associés au MS(erreur).
Si votre rapport F calculé dépasse la valeur attendue de la distribution F correspondante, alors, en supposant une valeur p suffisamment faible, vous devez rejeter l'hypothèse nulle selon laquelle les moyennes sont égales. La valeur p dans ce cas représente la probabilité d'observer une valeur supérieure au rapport F à partir de la distribution F lorsqu'en fait l'hypothèse nulle est vraie.