Cluster Subjects within Study Sites clusters subjects within study site for the purpose of identifying similar subjects. It constructs a cross domain data set using as much data as possible (subject to user options). Next, it calculates Euclidean distances to compute a distance matrix and performs hierarchical clustering of subjects within each study center. Findings values are averaged by USUBJID, test code, visit number, and time point (if available) if there are multiple measurements for a visit or time point. The goal of this exercise is to identify pairs of subjects with a very small distance. This could be an indication that these subject are slightly modified copies of one another.
Running this report for Nicardipine using default settings generates the report shown below.

The Cluster Subjects Within Study Sites report shows the results of clustering of the subjects on the basis of different combinations of covariates. The results for each grouping are presented in a separate “section”.
This pane enables you to access and view the output plots and associated data sets on each section. Use the drop-down menu to view the section in the Results pane or remove the section and its contents from the Results pane.
Note: You might need to expand this pane to surface a scroll bar if the number of sections exceeds the spaces allotted.
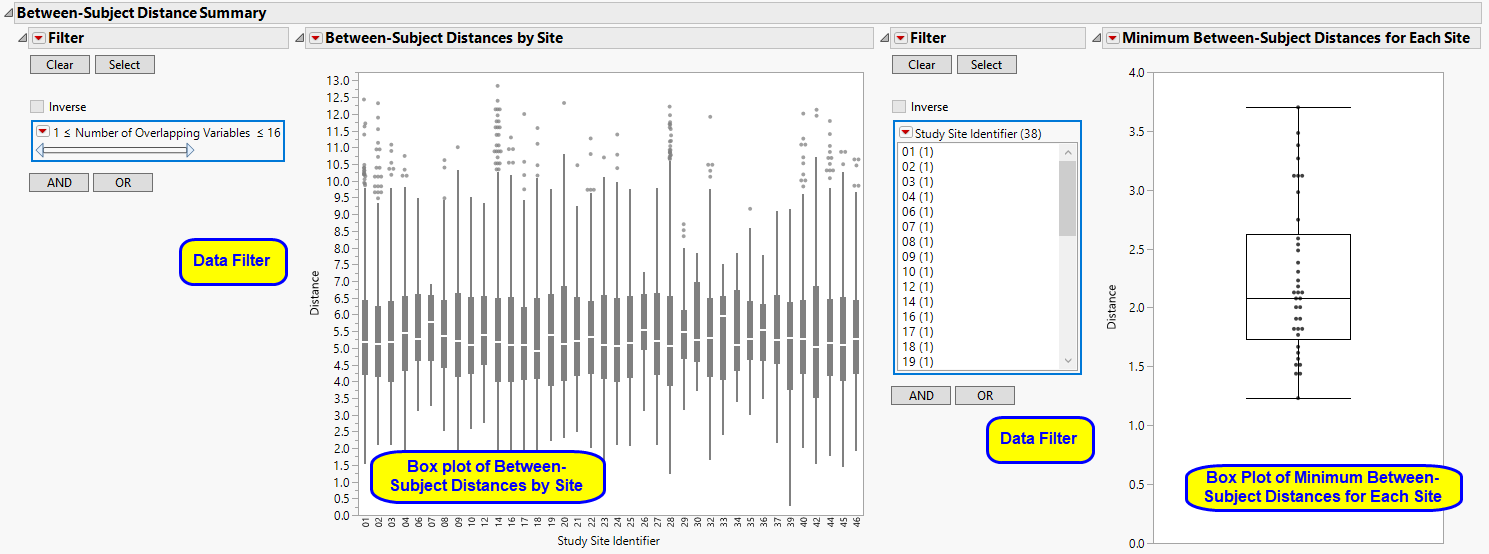
This section presents box plots of the pairwise Euclidian Distances between subjects presented by site. The Euclidian Distance is calculated within study site. A Box Plot of the minimum pairwise distance taken from each site presented is shown below.
These enable you to subset subjects by study site and the number of overlapping variables. Refer to Data Filter for more information.
The data filters for this report include an option to specify the Number of Overlapping Variables. One of the challenges in this report is that distances may be very small, even zero. This may be driven by the fact that a patient may have a number of missing values for variables, and these don't contribute to the distance calculation. By default, SAS calculates the distance between pairs of variables that are non-missing for each pair of subjects. Number of Overlapping Variables makes it easier to subset to pairs that have a high-number of non-missing overlapping pairs of variables.
|
•
|
This figure shows box plots of all pairwise Euclidian distances within each study site. Values closer to zero (0) reflect subjects that are very similar to one another, which could indicate that they are slightly modified copies.
|
•
|
One Box Plot of Minimum Between-Subject Distances for Each Site.
|
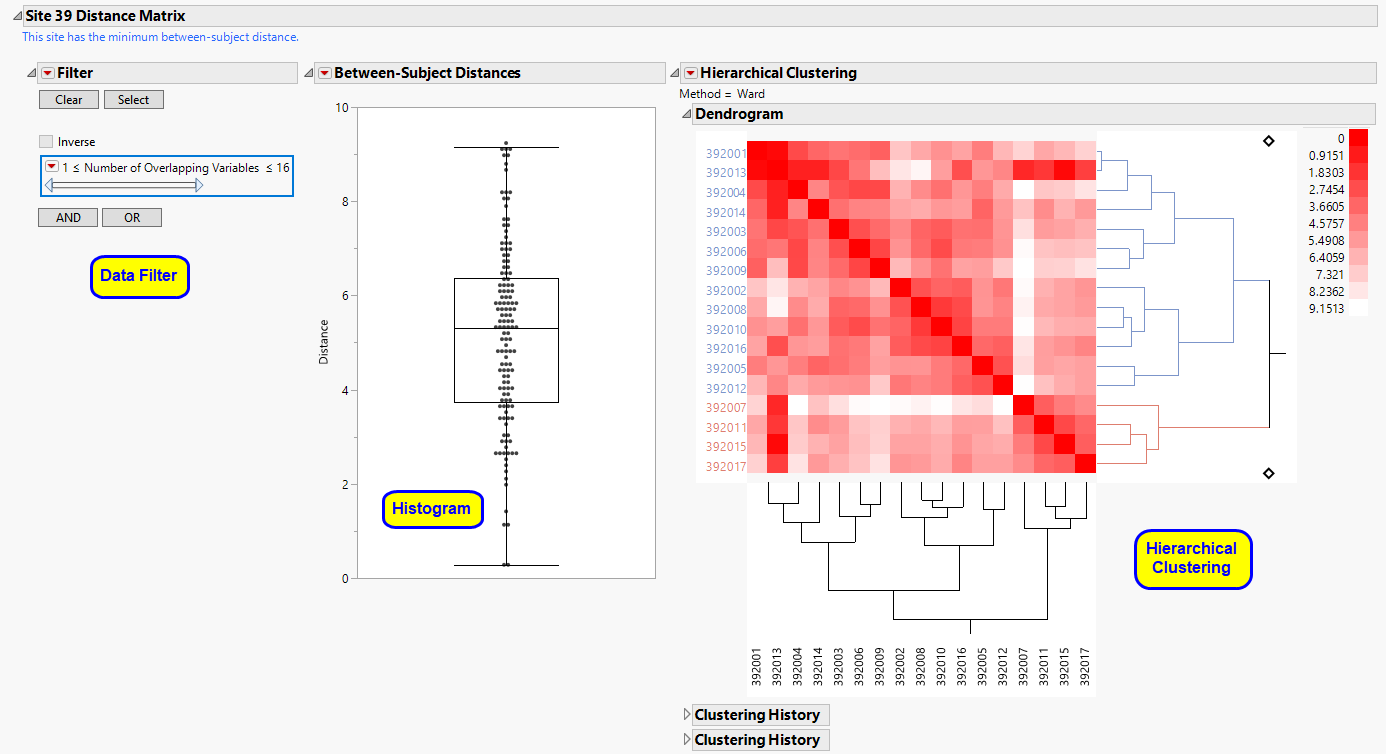
The Site XX Distance Matrix section is shown below. There is one section for each study site in the trial. However, only the site with the minimum pairwise distance is initially opened to minimize effects on performance. A box plot of all pairwise distances is presented as well as a Heat Map and Hierarchical Clustering display (using the Average method) to determine whether there are sets of subjects that are very similar.
This enables you to subset subjects based on the number of overlapping variables. Refer to Data Filter for more information.
|
•
|
One Box Pot
|
Summarizes the distribution of all pairwise Euclidian distances within site XX. Small pairwise distances can be selected in the Box Plot and highlighted in the Hierarchical Clustering Heat Map with the button.
|
•
|
One Hierarchical Clustering display.
|
Clusters subjects based on the pairwise Euclidian distances summarized in the box plot. Bluer color indicates subjects that are more similar, whereas red shows subjects less similar. The clustering dendrogram is presented to the right of the heat map and can show sets of more than two subjects that are similar to one another.
|
•
|
Profile Subjects: Select subjects and click
|
|
•
|
Show Subjects: Select subjects and click
|
|
•
|
Show Rows in Heat Map: Select points that represent pairs of subjects in the Box Plots and click
|
|
•
|
Subset Clustering: On a subgroup clustering page, subsets clustering to subjects, based on pairs selected from corresponding box plot.
|
|
•
|
Revert Clustering: Click
|
|
•
|
Click
|
Output includes one summary data set (named cswss_sum_XXX1, by default) containing one record per subject with selected data, one data set of all pairwise distances within the site (named cswss_alldist_XXX, by default), one data set containing minimum pairwise distances for each site (named cswss_mindist_XXX), by default), one data set per site containing pairwise distances (named cswss_p_Y_XXX, by default, where Y is site number or indexed 1 to the number of sites) and one data set per site containing the distance matrix of subjects within the covariate subgroup (named cswss_Y_XXX, by default, where Y is site number or indexed 1 to the number of sites).
|
•
|
Click
|
|
•
|
Click
|
|
•
|
Click
|
|
•
|
Click the arrow to reopen the completed report dialog used to generate this output.
|
|
•
|
Click the gray border to the left of the tab to open a dynamic report navigator that lists all of the reports in the review. Refer to Report Navigator for more information.
|
No testing is performed. Subjects are clustered within each site according to the selected clustering methodology. See statistical details for hierarchical clustering in the JMP documentation.
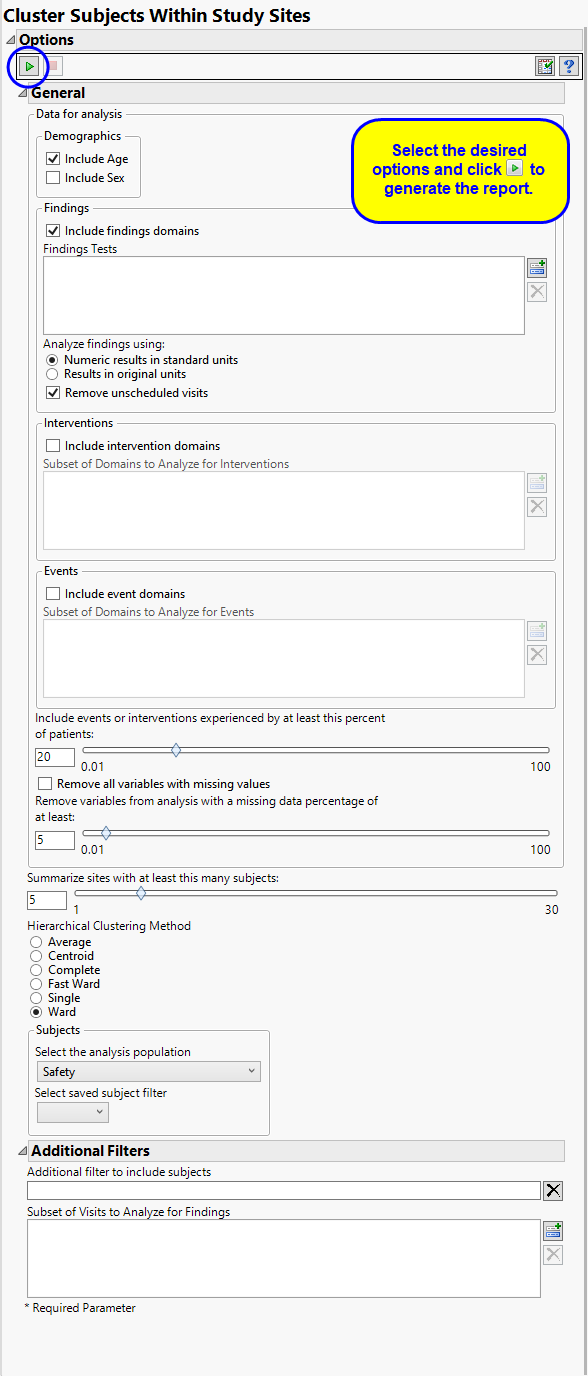
By default, the analysis Include Age. You can opt to Include Sex, as well, or to ignore either these if you choose.
You can opt to Include findings domains data. While all tests from all findings domains are included in the analysis by default, you can restrict the analysis to specified Findings Tests only. You can also select analysis units along with cutoff values for including events or interventions, for summarizing subgroups, and specify whether variables with missing values are allowed. You can Analyze findings using: either standard units or the original units.
Unscheduled visits can occur for a variety of reasons and can complicate analyses. By default, these are excluded from this analysis. However, by unchecking the Remove unscheduled visits box, you have the option of including them.
You can opt to Include intervention domains data in your analysis. By default, all intervention domains are included, however, you can use the Subset of Domains to Analyze for Interventions option to restrict the analysis to specific domains.
You can opt to Include event domains data in your analysis. By default, all event domains are included, however, you can use the Subset of Domains to Analyze for Events option to restrict the analysis to specific domains. Use the Include events or interventions experienced by at least this percent of patients: option to specify a minimum threshold for including an event or intervention in the analysis.
Finally, you can exclude variables missing some or any values. See Remove all variables with missing values, and Remove variables from analysis with a missing data percentage of at least: for more information.
The Summarize subgroups with at least this many subjects option enables you to generate summaries of significant subgroups of patients.
By default, specified subjects are clustered Ward’s Hierarchical Clustering Method.
Filters enable you to restrict the analysis to a specific subset of subjects based on values within variables. You can also filter based on population flags (Safety is selected by default) within the study data.
See Select the analysis population, Select saved subject Filter2, Additional Filter to Include Subjects, and Subset of Visits to Analyze for Findings for more information.
The _XXX designation is used to designate a one- to three-digit number that is added sequentially to prevent overwriting of existing data sets.
Subject-specific filters must be created using the Create Subject Filter report prior to your analysis.