Running this process using the GeneticMarkerExample sample setting generates the Results window shown below. Refer to the Haplotype Trend Regression process description for more information.
|
•
|
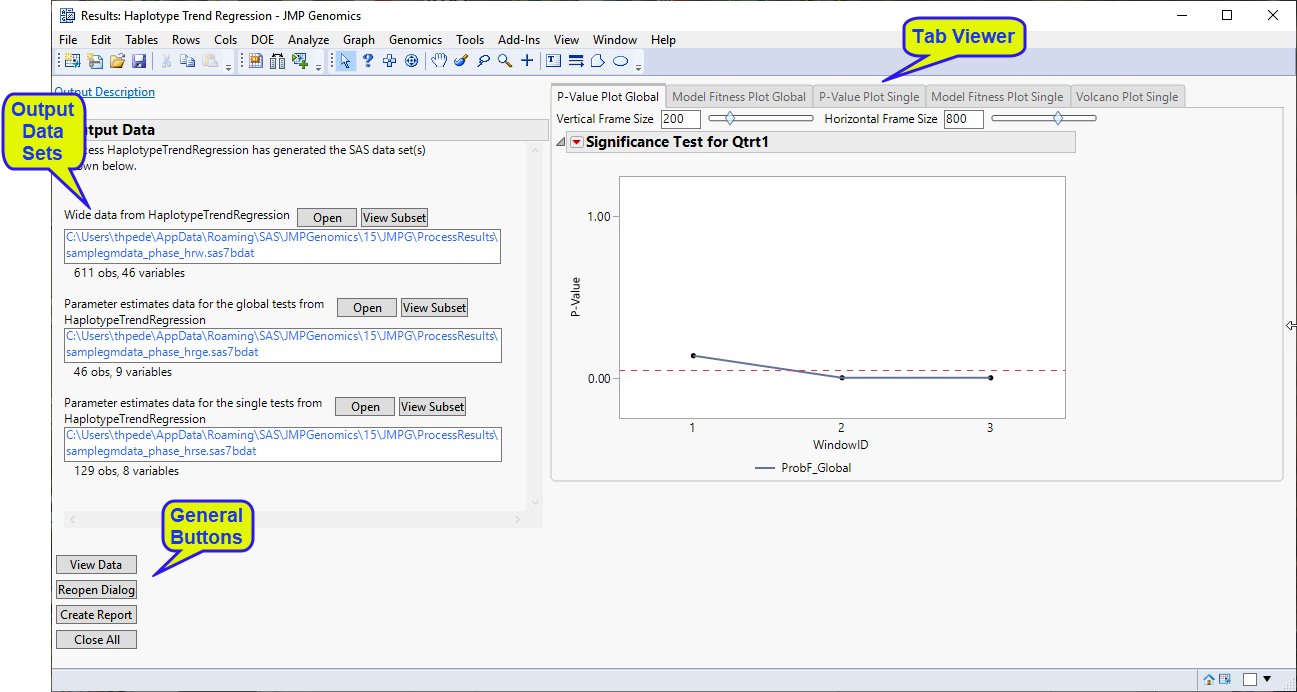
P-Value Plot Global (Haplotype Trend Regression): This tab includes a plot that displays the p-values (y-axis) from the global model (all haplotypes belonging to a window are tested together) for each window ID (x-axis).
|
|
•
|
Model Fitness Plot Global (Haplotype Trend Regression): This tab includes a plot that displays model information criteria value (y-axis) from the global model (all haplotypes belonging to a window are tested together) for each window ID (x-axis).
|
|
•
|
P-Value Plot Single (Haplotype Trend Regression): This tab includes a plot that displays the p-values (y-axis) from the single model (each haplotype belonging to a window is tested individually) for each haplotype ID (x-axis).
|
|
•
|
Model Fitness Plot Single (Haplotype Trend Regression): This tab includes a plot that displays model information criteria value (y-axis) from the single model (each haplotype belonging to a window is tested individually) for each haplotype ID (x-axis).
|
|
•
|
Volcano Plot Single (Haplotype Trend Regression): This tab displays a scatter plot of p-value (y-axis) by the Estimate of Haplotype Effect (x-axis) from the single model (each haplotype belonging to a window is tested individually).
|
|
•
|
Wide Data Set: This data set lists the relative occurrence of each potential haplotype. The name of this data is set is given by the Output File Prefix or input data set name, if no prefix is specified, with the suffix _hrw.
|
|
•
|
Parameter Estimates Data for the Global Tests: This data set lists the global test statistic. The name of this data is set is given by the Output File Prefix or input data set name, if no prefix is specified, with the suffix _hrge.
|
|
•
|
Residual Data for the Global Tests: This data set contains columns of Individual ID Variables and residuals from the global model for each window ID. The name of this data is set is given by the Output File Prefix or input data set name, if no prefix is specified, with the suffix _hrgr.
|
Note: This data set is generated only for the global model (all haplotypes belonging to a window are tested together).
|
•
|
Predicted Data for the Global Tests: This data set contains columns of Individual ID Variables and predicted values from the global model for each window ID. The name of this data is set is given by the Output File Prefix or input data set name, if no prefix is specified, with the suffix _hrgp.
|
Note: This data set is generated only for the global model (all haplotypes belonging to a window are tested together).
|
•
|
Parameter Estimates Data for the Single Tests: This data set lists the F-statistics and associated probabilities for each of the estimated haplotypes on each window ID. The name of this data is set is given by the Output File Prefix or input data set name, if no prefix is specified, with the suffix _hrse.
|
For detailed information about the files and data sets used or created by JMP Life Sciences software, see Files and Data Sets.
|
•
|
Click to reveal the underlying data table associated with the current tab.
|
|
•
|
Click to reopen the completed process dialog used to generate this output.
|
|
•
|
|
•
|
Click to close all graphics windows and underlying data sets associated with the output.
|