Running this process generates the Results window shown below. Refer to the Complete Genomics Input Engine process description for more information.
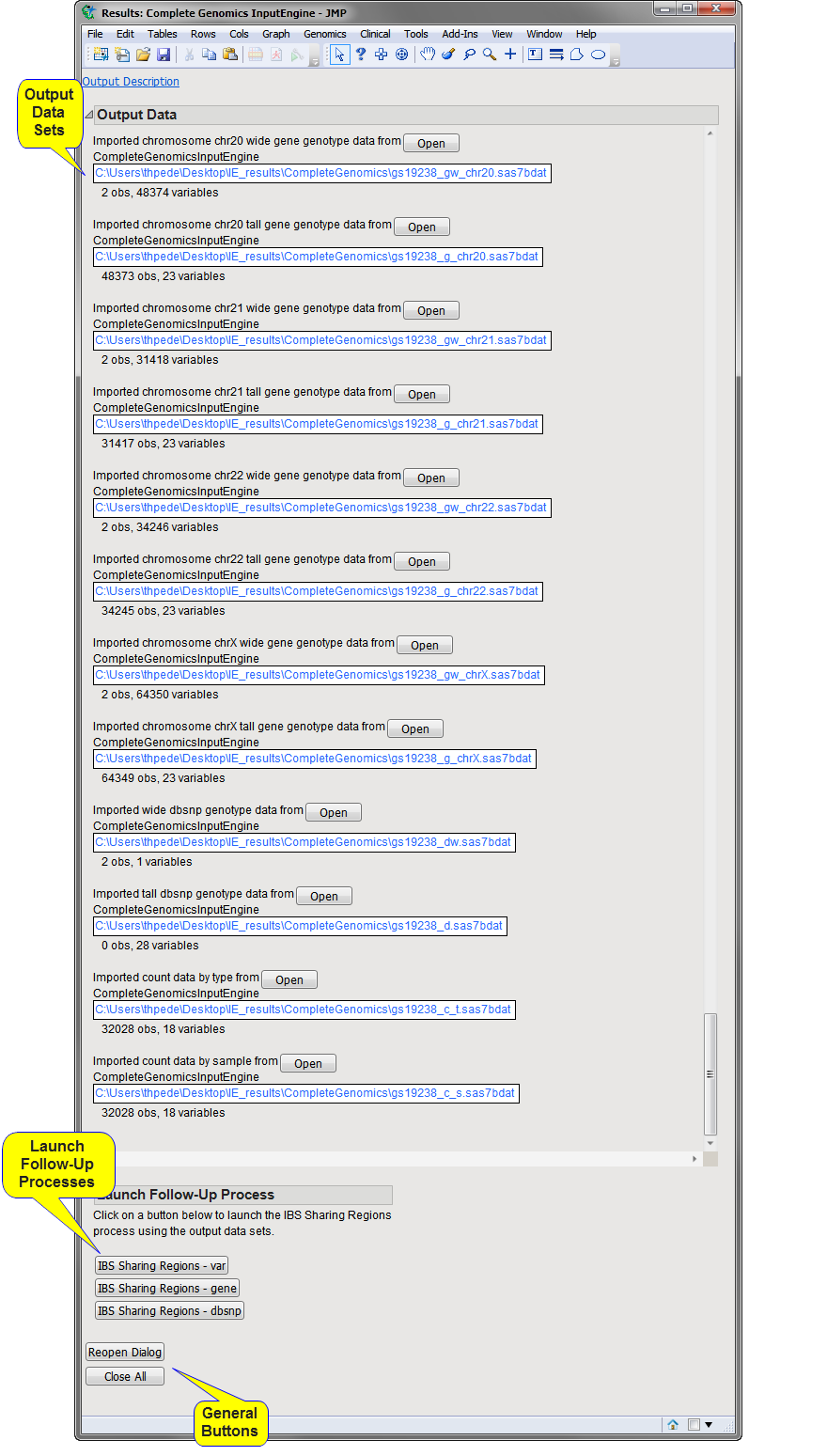
The Results window contains the following elements:
|
•
|
|
•
|
A wide variations genotype SAS data set per chromosome,
|
|
•
|
A tall annotated variants within known genes genotype SAS data set per chromosome,
|
|
•
|
A wide annotated variants within known genes genotype SAS data set per chromosome,
|
|
•
|
Output Variations Genotype Data Set (Tall): This data set lists genotype data imported from the input file(s) in tall data set format. Refer to Tall and Wide Data Sets for more information about tall data sets. One data set, designated by the _v suffix, is generated for each chromosome.
|
|
•
|
Output Variations Genotype Data Set (Wide): This data set lists genotype date imported from the csv file(s) in wide data set format. Refer to Tall and Wide Data Sets for more information about tall data sets. One data set, designated by the _vw suffix, is generated for each chromosome. Note: Wide data sets are generated only when the Create wide Output Genotype Data Sets check box is checked.
|
|
•
|
Output Annotated Variants within Known Genes Genotype Data Set (Tall): This data set lists genotype data imported from the input file(s) in tall data set format. Refer to Tall and Wide Data Sets for more information about tall data sets. One data set, designated by the _g suffix, is generated for each chromosome.
|
|
•
|
Output Annotated Variants within Known Genes Genotype Data Set (Wide): This data set lists genotype date imported from the csv file(s) in wide data set format. Refer to Tall and Wide Data Sets for more information about tall data sets. One data set, designated by the _gw suffix, is generated for each chromosome. Note: Wide data sets are generated only when the Create wide Output Genotype Data Sets check box is checked.
|
|
•
|
dbsnp Genotype Data Set (Tall): This data set lists variations at all known db SNP loci in tall data set format. Refer to Tall and Wide Data Sets for more information about tall data sets. One data set, designated by the _d suffix, is generated.
|
|
•
|
dbsnp Genotype Data Set (Wide): This data set lists variations at all known db SNP loci in wide data set format. Refer to Tall and Wide Data Sets for more information about tall data sets. One data set, designated by the _dw suffix, is generated.
|
|
•
|
Count Data by Type Data Set: This data set lists counts of variations by gene type. One data set, designated by the _c suffix, is generated.
|
|
•
|
Count Data by Sample Data Set:This data set lists counts of variations by gene sample summary. One data set, designated by the _c_s suffix, is generated.
|
Note: You can view the data in a file or data set by clicking either or (when the data set is very large).
|
•
|
IBS Sharing Regions - var: Click to launch the IBS Sharing Regions process with the Output Tall Variations Genotype data sets specified as input.
|
|
•
|
IBS Sharing Regions - gene: Click to launch the IBS Sharing Regions process with the Output Tall Annotated Variants within Known Genes Genotype data sets specified as input.
|
|
•
|
IBS Sharing Regions - dbsnp: Click to launch the IBS Sharing Regions process with the Output Tall dbsnp Genotype data sets specified as input.
|
|
•
|
Click to reopen the completed process dialog used to generate this output.
|
|
•
|
Click to close all graphics windows and underlying data sets associated with the output.
|