This process constructs the complete set of unique categories as defined by one or two delimiters in the annotation column, and computes a Fisher exact test, PAGE Z-Score tests (Kim and Volsky, 2005), or Cochran-Armitage trend tests. The resulting p-values can be adjusted for multiplicity using a variety of methods.
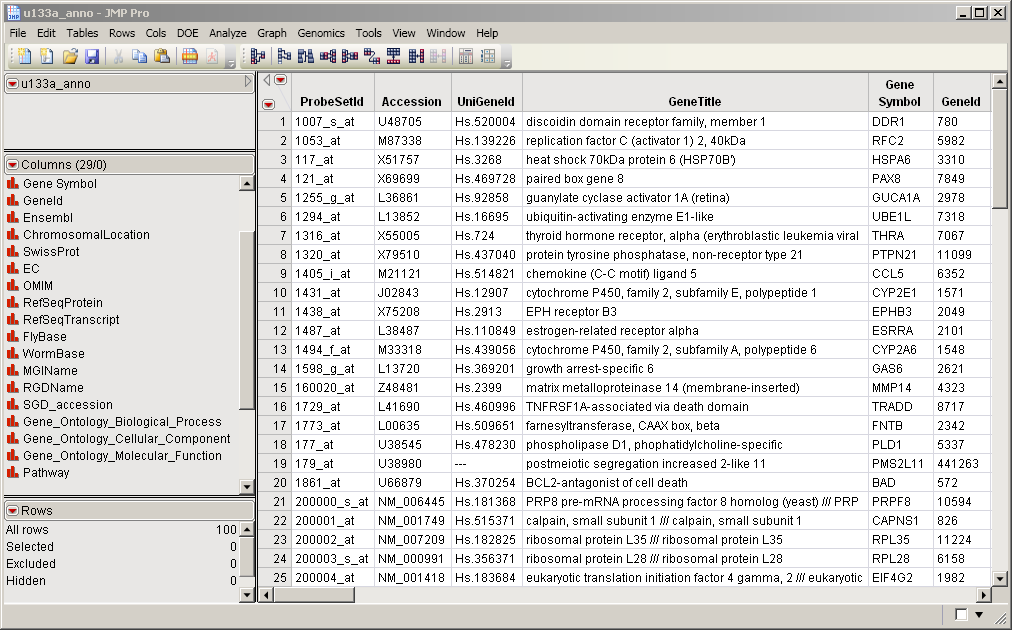
One Input Data Set is required to successfully run the Gene Set Enrichment process. This data set must contain at least one significance variable and an annotation column. The u133a_anno.sas7bdat input data set, shown below, contains annotation information and significance data from the Affymetrix Latin Square Data, and serves as an example.
|
•
|
The categories used in the enrichment are listed in the Gene_Ontology_Biological_Process column.
|
|
•
|
ProbF_Trt should be selected as one of the Significance Variables.
|
|
•
|
|
•
|
Enrich for genes whose expression is down-regulated, so select Smaller is more significant as the direction of significance variables.
|
|
•
|
Specify 0.01 as the significance variable cutoff for the Fisher exact test.
|
|
•
|
For detailed information about the files and data sets used or created by JMP Life Sciences software, see Files and Data Sets.
Refer to the Gene Set Enrichment output documentation for detailed descriptions of the output of this process.