The One-Way ANOVA process provides a rapid means for an initial assessment of the data. It differs from the standard ANOVA process in a number of important ways. A comparison of the capabilities of both processes is shown below.
|
Ability to distinguish effects of variables independently and in combination
|
||
Instead of looking at all possible effects and their interactions separately, One-Way ANOVA considers all of the combinations of different effects as distinct groups. Because of this, and unlike the standard ANOVA process, it does not and cannot examine each variable and combination of variables independently of each other. However, because its scope is more limited, One-Way ANOVA can handle very large data sets quickly and efficiently, identifying preliminary items of interest that can be further defined in subsequent and more thorough analyses.
|
•
|
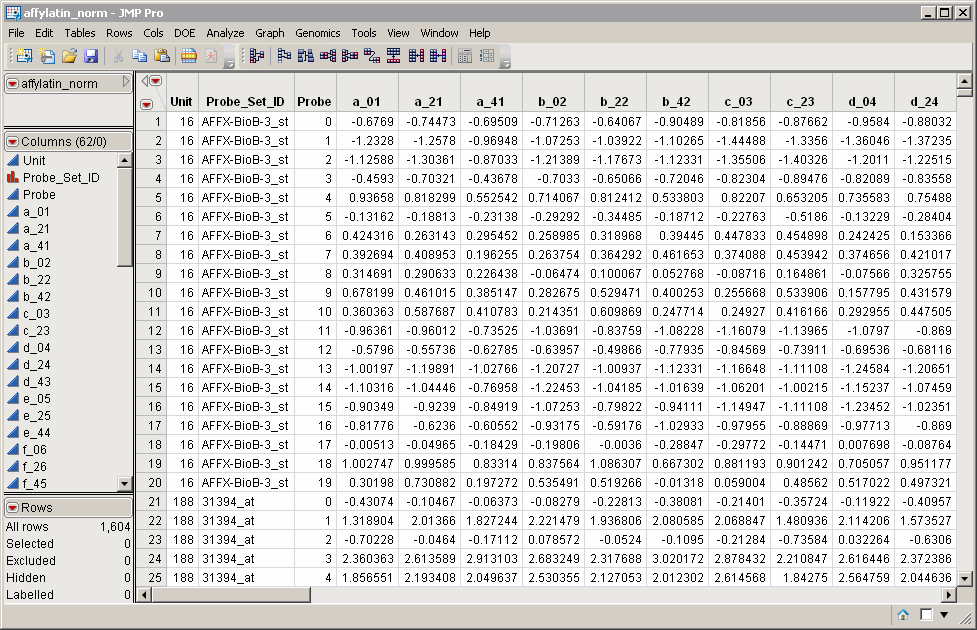
The Input Data Set that contains all of the numeric data to be analyzed. For most cases, the use of normalized data, in which global effects (such as dye, chip to chip variation, and so on) have been removed, is recommended. The affylatin_norm.sas7bdat data set is a normalized data set derived from the Affymetrix Latin Square Experiment described in Affymetrix Latin Square Data, and serves as an example. It has 62 columns and 1604 rows. Note that this is a tall data set; each probe corresponds to one row whereas each column corresponds to separate experimental condition.
|
|
•
|
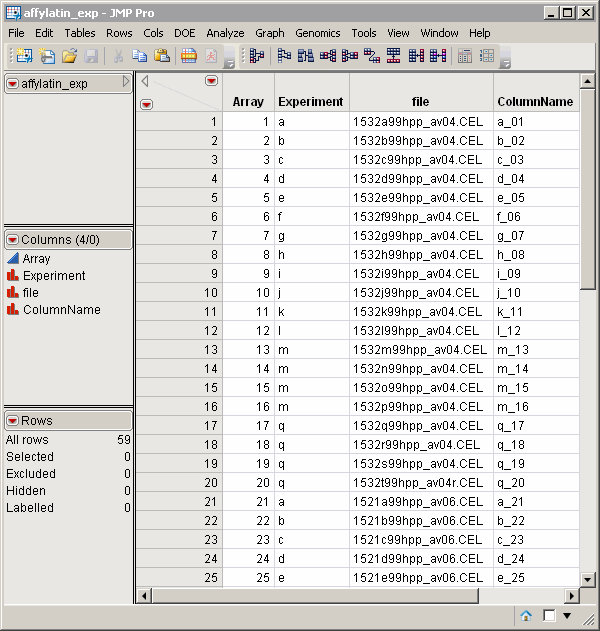
The Experimental Design Data Set (EDDS). The affylatin_exp.sas7bdat EDDS serves as an example. This required data set tells how the experiment was performed, providing information about the columns in the input data set. Note that one column in the EDDS must be named ColumnName and the values contained in this column must exactly match the column names in the input data set. Two other columns in this data set, Array and Experiment, correspond to an index variable and the one-way experimental variable, respectively.
|
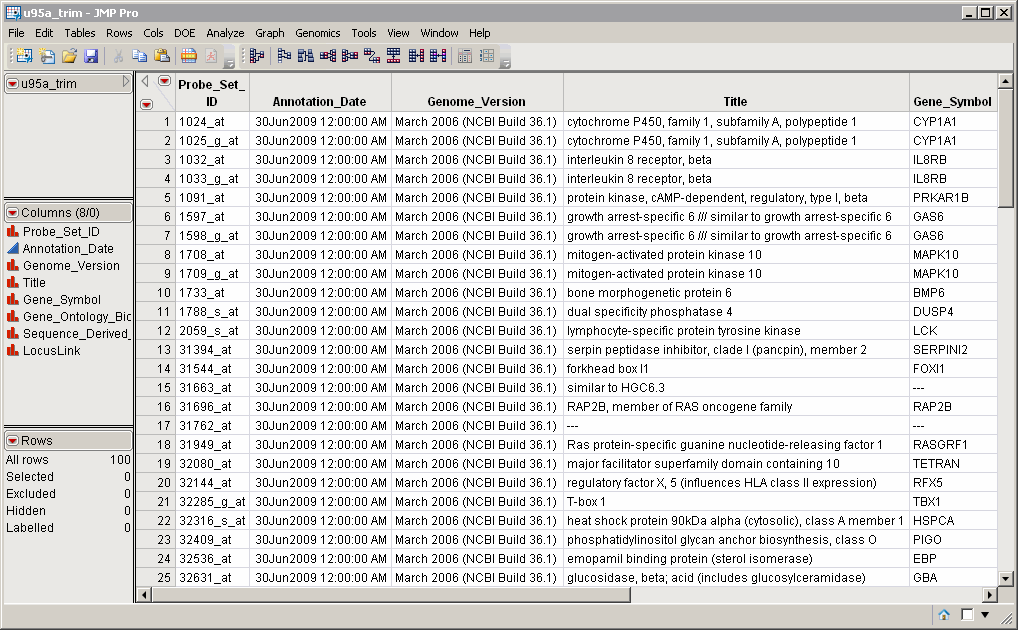
An Annotation Data Set is optional. This data set contains information such as gene identity or chromosomal location, for each of the rows in the input data set. The u95a_trim.sas7bdat data set identifies spots, accession number, and gene identities (where known), and serves as an example. This represents a subset of the U95a array annotation data set downloaded from NetAffx. This data set is also in the tall format, where each row corresponds to a different gene. The variable Probe_Set_ID is used as a merge key to join the input data set to the annotation data.
The afflylatin_norm.sas7bdat, afflylatin_exp.sas7bdat, and u95a_trim.sas7bdat data sets are included in the Sample Data folder that comes with JMP Genomics.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see Files and Data Sets.
The output generated by this process is summarized in a Tabbed report. Refer to the One-Way ANOVA output documentation for detailed descriptions and guides to interpreting your results.