The Control Set Normalization process normalizes data by subtraction of (the mean or median value of) control sample measurements or arrays, from experimental samples. The subtraction can be done either within subject (for example, replicate arrays per unique subjects) or across a set or sets of experimental subjects and control subjects.
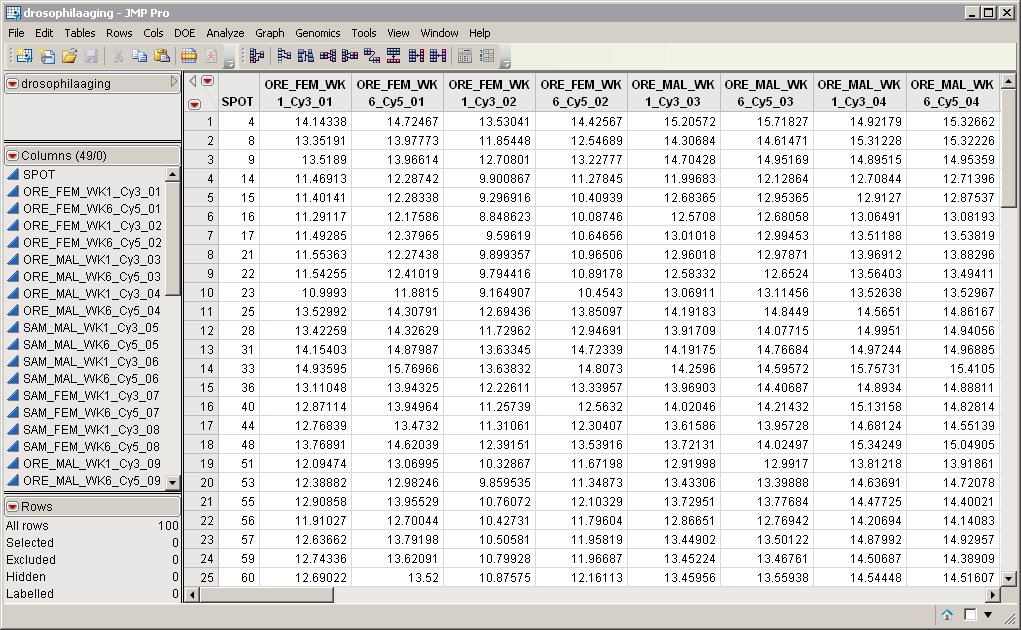
Two data sets are required for this process. The first, the Input Data Set, contains all of the numeric data to be analyzed. The drosophilaaging.sas7bdat data set from the Drosophila aging experiment of Jin, et al. (2001) that is described in Drosophila Aging Experimental Data serves as an example, and is shown below. It has 48 data columns and 100 rows. Note that this is a tall data set; each probe corresponds to one row whereas each column corresponds to a separate experimental condition.
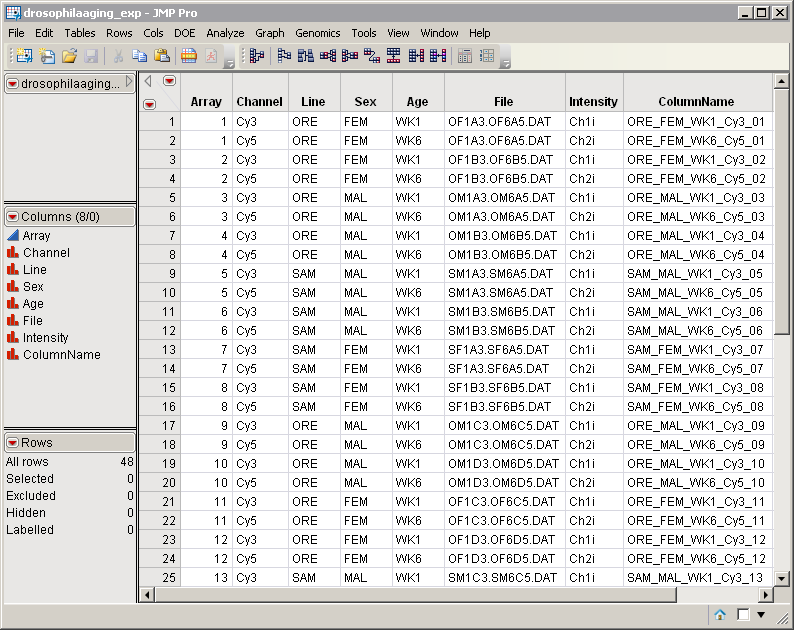
The second data set is the Experimental Design Data Set (EDDS). The drosophilaaging_exp.sas7bdat EDDS serves as an example, and is shown below. This required data set tells how the experiment was performed, providing information about the columns in the input data set. Note that one column in the EDDS must be named ColumnName and the values contained in this column must exactly match the column names in the input data set.
The raw data from this experiment were evaluated using Distribution Analysis. The Overlay Plot shown below illustrates the raw univariate distributions of all 48 channels from the 24 arrays.
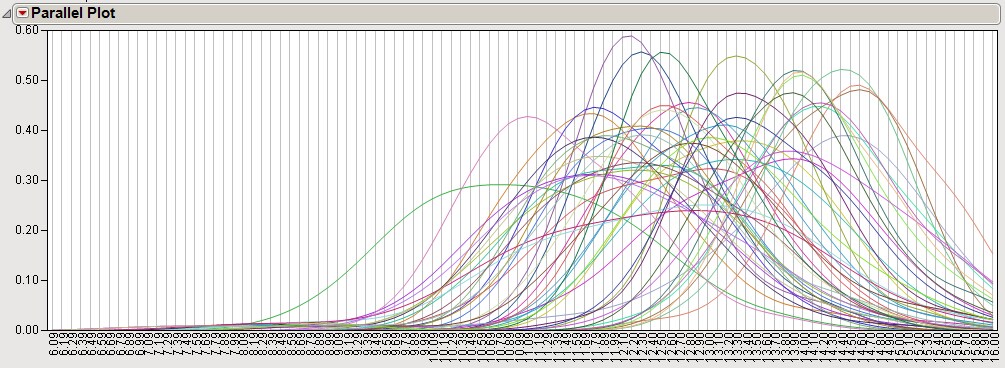
Visually, the estimated distributions significantly vary among all the 48 channels here. This inherent variability among arrays and dye indicates that normalization across arrays and channels is essential for effective analysis of these data.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see Files and Data Sets.
Refer to the Control Set Normalization output documentation for detailed descriptions of the output of this process.