Instead of examining markers individually, it can often be more informative to look at a set of alleles and markers from the same chromosome as a single entity, that is, as a haplotype. However, when genotype data are collected, the two haplotypes that compose a multilocus genotype are not typically observed. Thus, the alleles, passed together from one parent, for each of the set of markers, remain unknown. The first step in any haplotype analysis is typically to estimate the unobserved haplotype frequencies (Haplotype Estimation). Estimates of haplotype frequencies can be used in a variety of ways: to test for multilocus linkage disequilibrium, to test for association between a trait and several markers at once, and to infer the parental haplotypes that an individual receives.
The Haplotype Trend Regression process uses information about the individuals' probabilities for haplotype pairs (the Phase Assignment data set from the Haplotype Estimation process), to test for association of each haplotype with a quantitative trait using PROC GLM, a binary trait with PROC LOGISTIC, a count trait using PROC GLIMMIX or a survival trait with PROC PHREG.
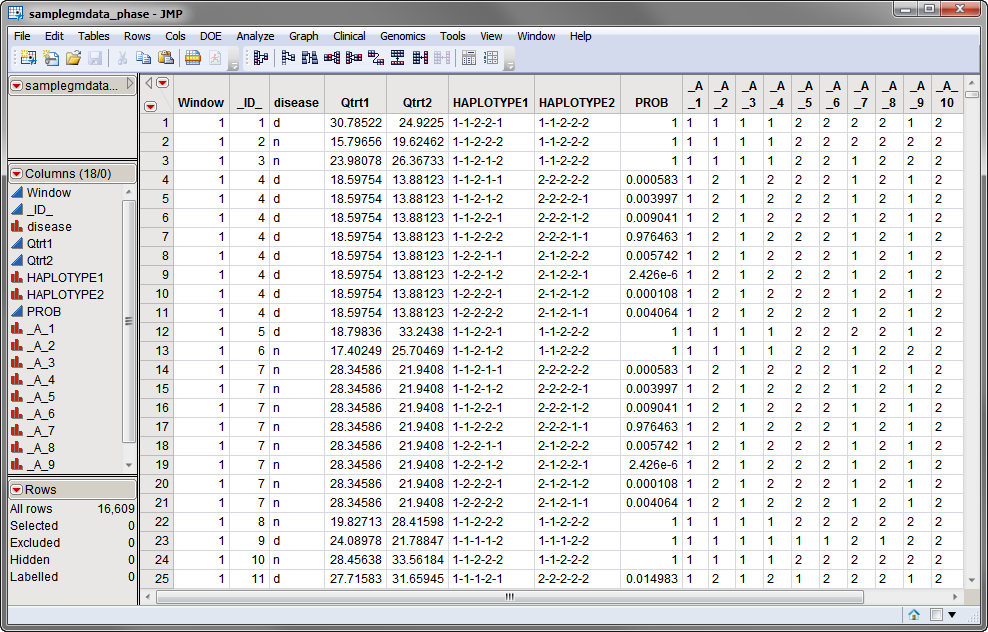
One data set, the phase assignment data set, is required to run the Haplotype Trend Regression process. The samplegmdata_phase.sas7bdat data set, shown below, was generated using the Haplotype Estimation process from data contained in the samplegmdata.sas7bdat data set. The samplegmdata.sas7bdat data set, described in Data Sets Used in JMP Genomics Processes, was computer generated and consists of 1000 rows of individuals with 130 columns corresponding to data on these individuals. The Individual ID, disease, Qtrt1, and Qtrt2 columns were selected as ID variables from the original data set and were included in the samplegmdata_phase.sas7bdat data set. Haplotypes, defined by sliding windows encompassing 5 adjacent markers, are listed in a pair of columns. The probability of observing the co-occurrence of a specific pair of haplotypes in an individual is listed. Different haplotype pairs contain the alleles listed in columns _A_1 through _A_10 at the five markers in the sliding window.
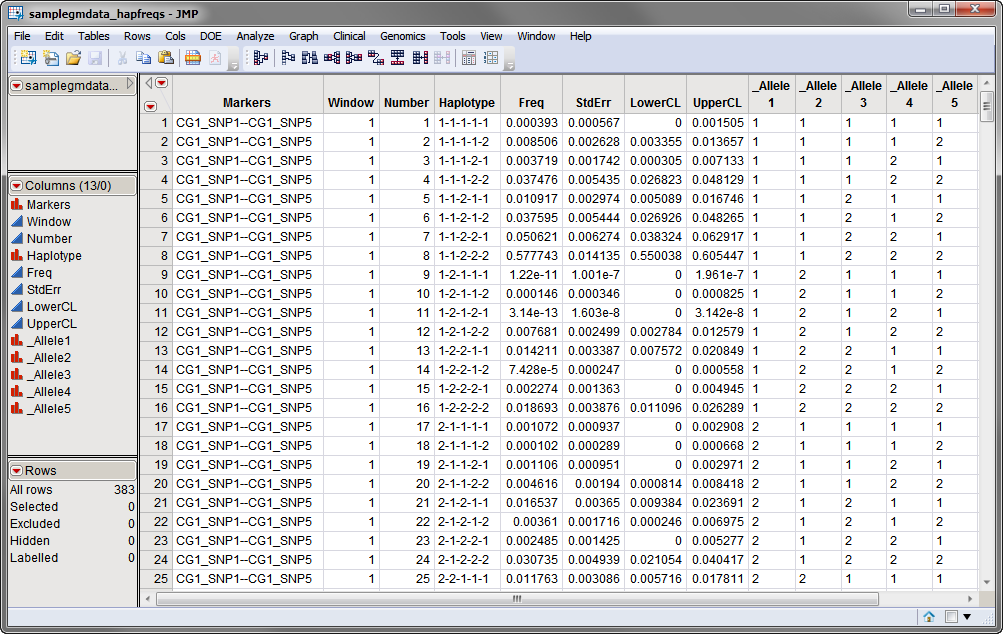
A second, optional, data set, the haplotype frequency data set, lists the estimated frequencies for each of the haplotypes for the original data set. These frequencies are used for identifying and combining rare haplotypes if a value greater than 0 is entered for the Frequency Cutoff for Combining Haplotypes parameter. The samplegmdata_hapfreqs.sas7bdat data set, shown below, was generated from the samplegmdata.sas7bdat data set using the Haplotype Estimation process.
Both the samplegmdata_phase.sas7bdat and samplegmdata_hapfreqs.sas7bdat data sets are contained in the Sample Data folder included with JMP Genomics.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see Files and Data Sets.
Output from this process is accessed from a Results window. Refer to the Haplotype Trend Regression output documentation for detailed descriptions and guides to interpreting your results.