Most of the processes in JMP Genomics assume that the input SAS data set has a particular data structure. JMP Genomics distinguishes between tall and wide SAS data sets. A tall SAS data set has samples as columns, and molecular entity (such as marker, gene, clone, protein, or metabolite) as rows. A wide SAS data set is the transpose of a tall data set, having the samples as rows and molecular entity as columns. When specifying the input SAS data set for a process, it is important to know the required form. Most of the processes associated with genetic analyses require a wide structure, whereas most of those for microarray and proteomics analyses use a tall structure.
Filter Wide Columns Based on Tall Rows enables you to remove columns from a wide data set based on a filter specified using variables from the corresponding tall data set to filter its rows.
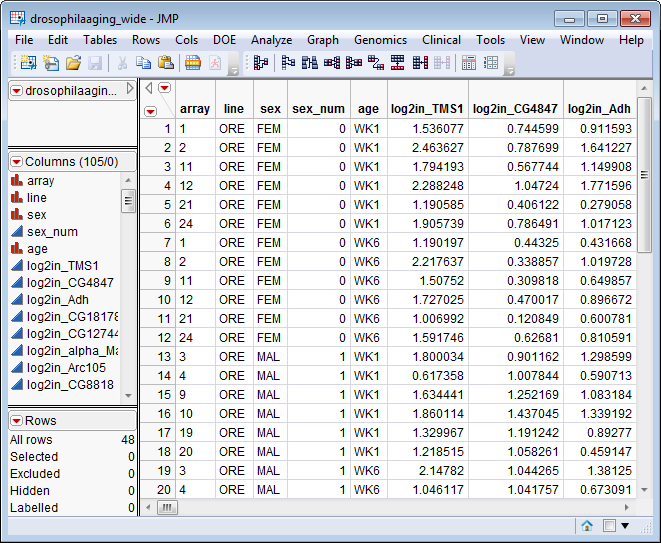
The drosophilaaging_wide.sas7bdat file (located in the \LifeSciences\Sample Data\Microarray\Scanalyze Drosophila directory included with JMP Genomics, associated with the Drosophila aging experiment of Jin, et al. (2001) and described in Drosophila Aging Experimental Data) serves as an example Wide SAS Data Set.
The drosophilaaging_tall.sas7bdat file (located in the \LifeSciences\Sample Data\Microarray\Scanalyze Drosophila directory included with JMP Genomics, associated with the Drosophila aging experiment of Jin, et al. (2001) described in Drosophila Aging Experimental Data) serves as an example Tall SAS Data Set.
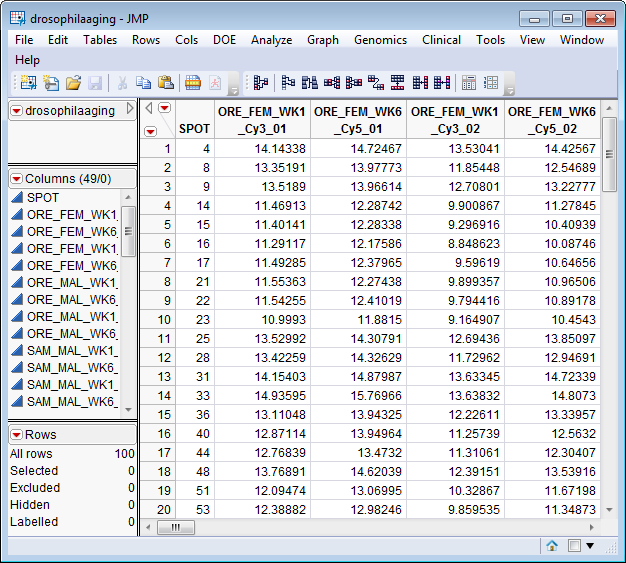
In this example, all variables starting with log2in_ are Wide Variables Corresponding to Tall Rows. Rows from the tall data set (and the corresponding columns from the wide data set) are to be included only if the value of SPOT exceeds 100.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see Files and Data Sets.
The output from this process consists of a Results window, which lists the two subsetted data sets:
|
•
|
The subsetted wide data set, and
|
|
•
|
The subsetted tall data set.
|
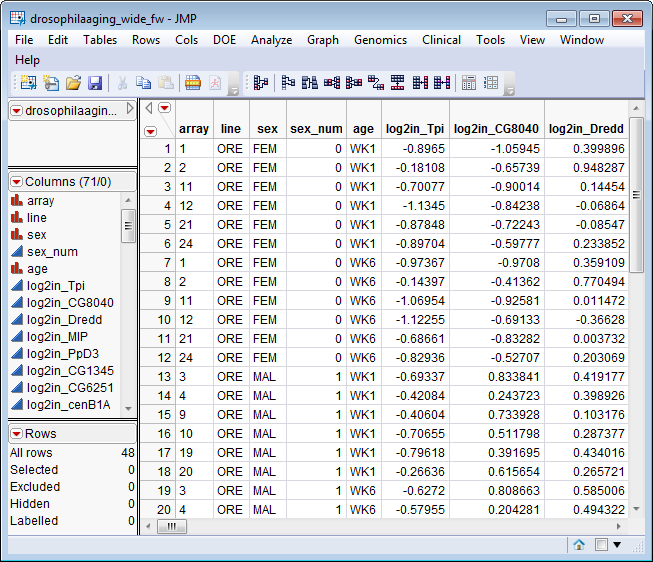
The first column beginning with log2in_ listed in the subsetted wide data set is log2in_Tpi. This is the 35th log2in_ column listed in the Input Wide Data Set. It corresponds to the 35th row of the Input Tall Data Set, which is the first row where the value of SPOT exceeds 100. All subsequent columns in the subsetted wide data set correspond to the rows in the Input Tall Data Set after the 35th row (and the columns in the Input Wide Data Set after the 35th log2in_ column).
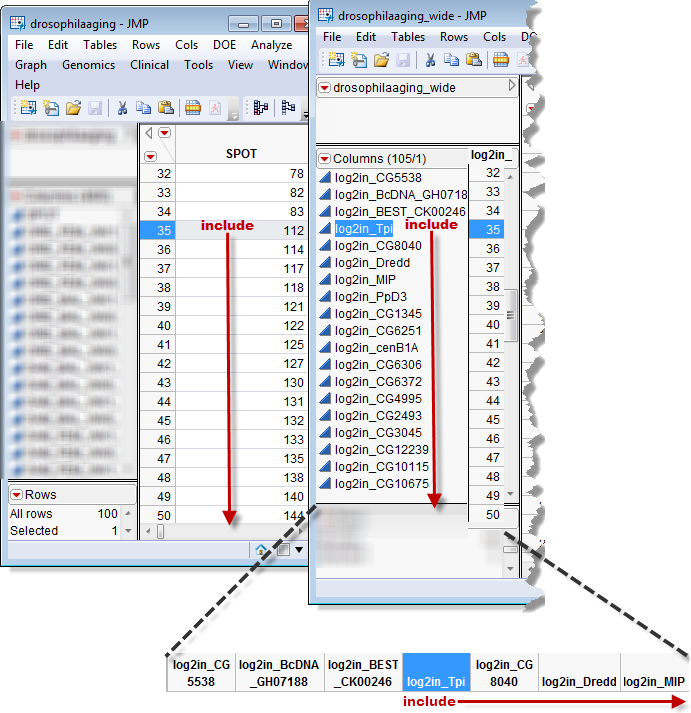
Only those rows where the SPOT value exceeded 100 were kept (row 35, onward). This consequently means that only log2in_ column 35, onward, were kept in the subsetted wide data set.