The Cumulative Plots tab is shown below:
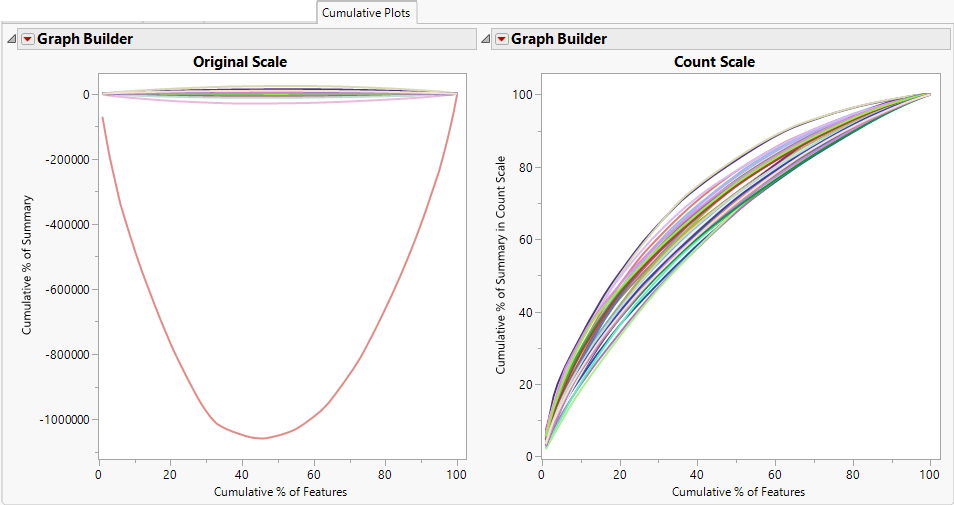
This tab displays two plots in the original (log2) scale from the input data set and the count scale (taking 2 to the power of corresponding value) showing the relative contribution of different genes to the total summary of data and how much the overall signal can be dominated by the top expressers.
Each line in the plots represents an individual sample. The y-axis indicates the percentage of accumulative summary from largest to smallest values as compared to the overall summary of all values. The x-axis indicates the percentage of genes applied for the cumulative summary. While all of the lines in both plots are concave, with one exception, the lines in the log-scale plot (left) are much closer to linearity than the corresponding lines in the count scale plot (right) where samples with the highest expression are added first. (Subsequent genes are added in order of decreasing expression.) In this case, the percentage of the accumulative summary in count scale increases sharply when adding up a small percentage of top expressed genes. As can be seen, the top 10-15% of the expressers contribute a vastly higher percentage of the counts, whereas the remaining 80-90% contribute relatively little to the overall signal.
These plots show that, in this experiment, the overall expression is skewed by a relative few highly expressed genes in count scale. In this case, RPM Scaling (or RPKM scaling), where the total mapped reads, the summary of all genes in count scale, is applied to each individual sample as the sample associated divisor to rescale count values for RNAseq data, might not always be the best choice. To prevent the data from being dominated by a few very high expressers, you might want to apply either KDMM Normalization or Upper Quartile Scaling, which do not reply on total mapped reads for the normalization process.