Output Description
Concatenate Data
Running this process for the TallFiles sample setting generates the Results window shown below. Refer to the Concatenate Data process description for more information.
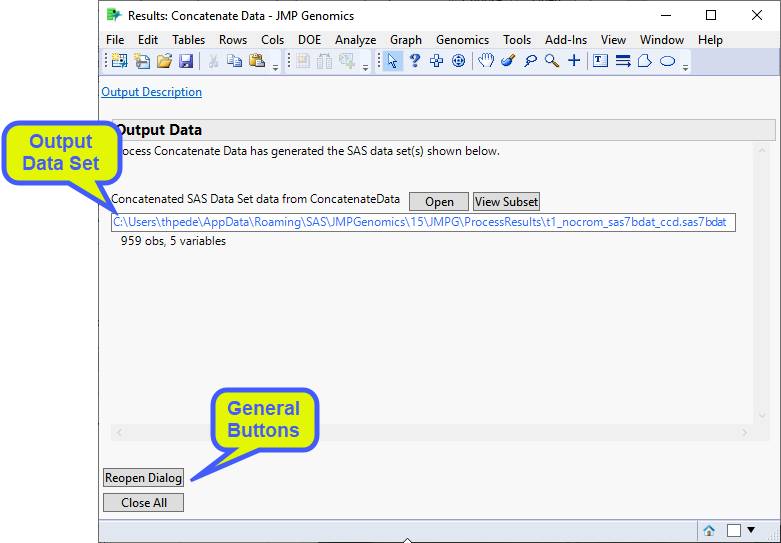
The Results window contains the following elements:
Output Data
This process generates one concatenated data set (with the _ccd suffix) that is shown below. This data set consists of 5 of the columns from the input data sets. (Note: The sample setting used in this example drops all but 5 columns the input data sets.) The rows from the first input data set are are stacked on top of the rows from the second which are then stacked on top of the rows from the third input data set. Note rows 911 and 912 are circled. these rows correspond to row 911 from the t1_noGT.sas7bdat data set and row 1 from the t2_noGT.sas7bdat data set that were highlighted in the Process Description.

| 8 | Click to view the data set. |
| 8 | Click to view a subset of the concatenated data set. This option is especially useful for very large data sets. |
General
| 8 | Click to reopen the completed process dialog used to generate this output. |
| 8 | Click to close all graphics windows and underlying data sets associated with the output. |
Additional Information
| • | If you elect to keep a column that is not present in all of the data sets, that column will be present in the output data set. It will have the same number of rows as all of the other columns. Missing values will be assigned to the rows corresponding to the data set(s) lacking the column. |
| • |