Process Description
htSNP Selection
Instead of examining markers individually, it can often be more informative to look at a set of alleles and markers from the same chromosome as a single entity, that is, as a haplotype. However, when genotype data are collected, the two haplotypes that compose a multilocus genotype are not typically observed. Thus, the alleles, passed together from one parent, for each of the set of markers, remain unknown. The first step in any haplotype analysis is typically to estimate the unobserved haplotype frequencies (Haplotype Estimation). Estimates of haplotype frequencies can be used in a variety of ways: to test for multilocus linkage disequilibrium, to test for association between a trait and several markers at once, and to infer the parental haplotypes that an individual receives.
The htSNP Selection process uses observed or estimated haplotype frequencies to identify subsets of htSNPs (haplotype tag SNPs): a subset of markers that can be used to explain much of the haplotype diversity. The Haplotype Estimation process can be run first in order to create an Input Data Set in the appropriate format. An .html file and a JMP plot are both created to display the results. See the HTSNP procedure in the SAS/Genetics User's Guide for more information about the options in this process.
What do I need?
One data set, the haplotype frequency data set, which lists the observed or estimated frequencies for each of the haplotypes from a genetic marker data set is needed to run the htSNP Selection process.
The samplegmdata_hapfreqs.sas7bdat data set, shown , was generated from the samplegmdata.sas7bdat data set using the Haplotype Estimation process and lists estimated frequencies for each of the haplotypes. The samplegmdata data set, described in Data Sets Used in JMP Genomics Processes, was computer generated and consists of 1000 rows of individuals with 130 columns corresponding to data on these individuals.
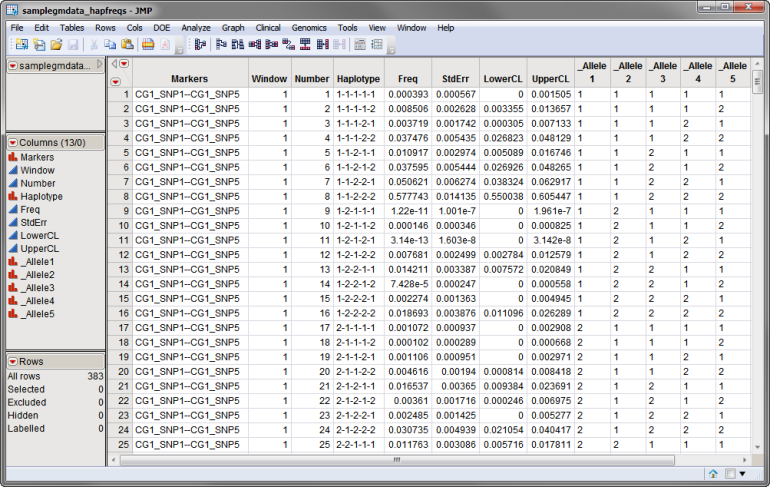
A second, optional, data set that can be used in the htSNP Selection process is an Annotation Data Set, This data set contains information, such as gene identity or chromosomal location, for each of the markers. The annotation data set used in this example, the samplemap.sas7bdat data set, was computer generated and identifies markers, location and gene identities. A portion of this data set is illustrated below. This data set is a tall data set; each row corresponds to a different marker.
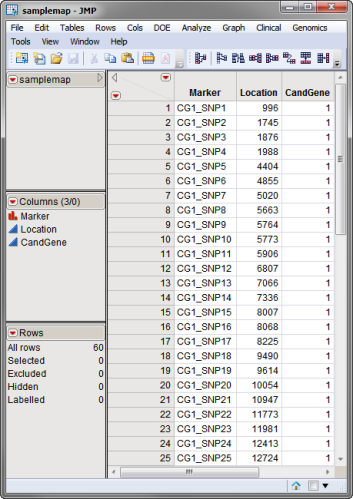
Both the samplegmdata_hapfreqs.sas7bdat haplotype frequency and samplemap.sas7bdat annotation data sets are located in the Sample Data folder included with JMP Genomics.
For detailed information about the files and data sets used or created by JMP Genomics software, see Files and Data Sets.
Output/Results
The output generated by this process is summarized in a Tabbed report. Refer to the htSNP Selection output documentation for detailed descriptions and guides to interpreting your results.