Process Description
Tassel-GBS Import Engine
The Tassel-GBS Import Engine transcodes output data from the TASSEL 3 Genotyping by Sequencing (GBS) pipeline into Input and Annotation SAS Data Sets ready for use in downstream JMP Genomics analytical processes.. The Annotation SAS Data Set contains columns of data summary and statistics relevant to downstream quality control analyses. The Input SAS Data Set contains columns of markers with coded genotypes for each individual in the sample.
What do I need?
One SAS data set is required to run the Tassel-GBS Import Engine.
The first required data set is a SAS data set containing a column holding marker names and columns of individuals holding coded genotypes. Genotypes must be coded as follows: A = A/A, C = C/C, G = G/G, T = T/T, M = A/C, R = A/G, W = A/T, S = C/G, Y = C/T, K = G/T, and N = missing). An example of such a data set, the gbs_2xbc1geno.sas7bdat data set, is shown below:
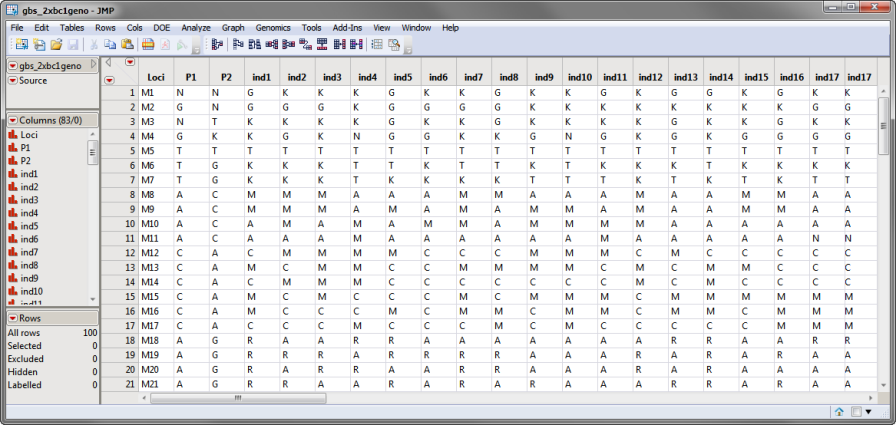
The gbs_2xbc1geno.sas7bdat data set contains 83 columns: loci are identified in column one (Loci), parental genotypes at each locus are listed in columns 2 and 3 (P1 and P2, respectively), and the genotypes of 80 individual progeny (ind1 - ind80) at each locus are listed in the remaining columns.
A second, optional, data set is the Annotation Data Set that lists marker map or other annotation information. The gbs_2xbc1anno.sas7bdat annotation data set is shown below:

For detailed information about the files and data sets used or created by JMP Genomics software, see Files and Data Sets.
Output/Results
The output data sets generated by this process are listed in a Results window. Refer to the Tassel-GBS Import Engine output documentation for detailed descriptions.