Running this process for the
ProstateCancerExample
sample setting generates one output data set accessed from a
Results
window shown below. Refer to the
2D Bin
process description for more information about this process.
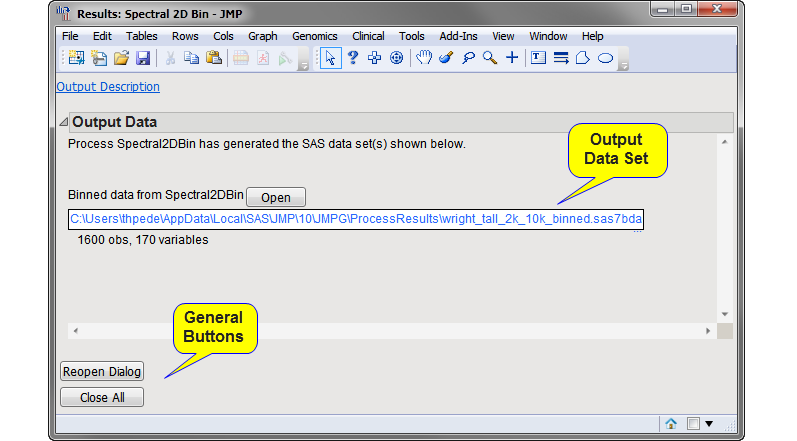
The
Results
window contains the following panes:
|
•
|
Output Binned Data Set
: The
output data set consists of all of the columns from the input data set plus four additional columns (highlighted in the figure below). This data set has the
_binned
suffix appended to the name of the input data set. Click
to view the output data set.
|
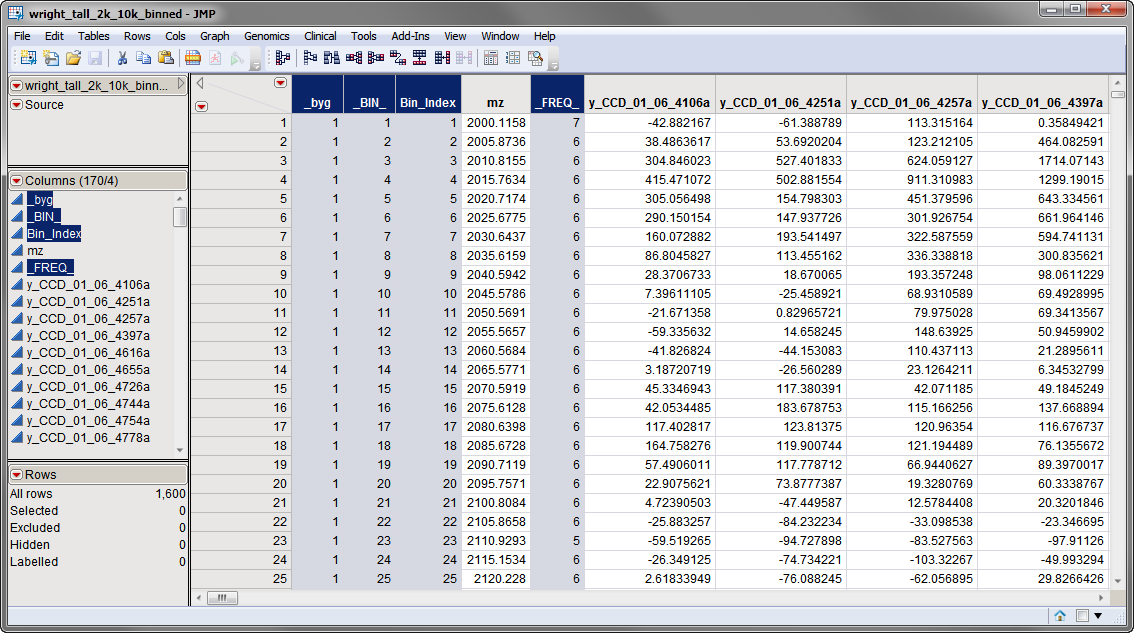
Four additional columns have been added to the output data set. The
_byg
column indexes
BY groups
. In this example, no
BY variables
were specified, so every row is indexed to the same value (
_byg
=1). The
_BIN_
column sequentially indexes all
bins
and accumulates across
By
groups, whereas the
Bin_Index
column starts at 1 for each new
By
group. Because no
By
variables were specified in this example, the two
variables
are identical across all rows. The
_FREQ_
column indicates the number of rows binned together. Binning rows has reduced the total number of rows from 6,016 down to 1,600 (almost 4-fold reduction).
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
|
•
|
Click
to reopen the completed process dialog used to generate this output.
|
|
•
|
Click
to close all graphics windows and underlying data sets associated with the output.
|