The
RPM (Reads Per Million) Scaling
process is a straightforward
normalization
method for Count data. It divides the raw read count by the total number of mapped reads, and multiplies the result by 1,000,000.
For additional details, please refer to
Motameny et al.
(Genes 2010).
Two data sets are
required
by this process:
|
•
|
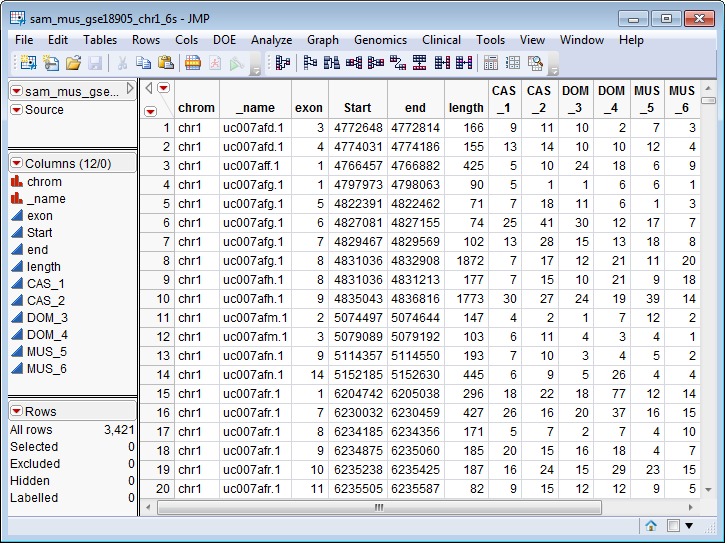
A SAS
Input Data Set
containing count data. The
sam_mus_gse18905_chr1_6s.sas7bdat
data set serves as an example, and is shown below. This is a
tall
data set, with 12 columns and 3,421 rows.
|
|
•
|
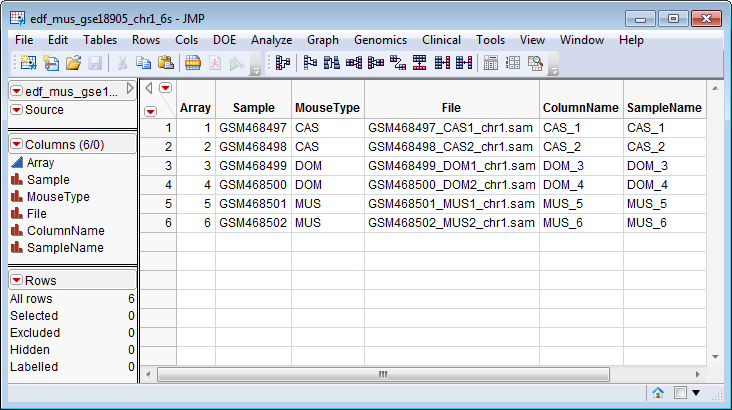
An
Experimental Design Data Set (EDDS)
. This data set tells how the experiment was performed, providing information about the columns in the input data set. Note that one column in the EDDS must be named
ColumnName
and the values contained in this column must exactly match the column names in the input data set. The
edf_mus_gse18905_chr1_6s.sas7bdat
data set serves as an example, and is shown below.
|
Note
: The EDF for this process requires an additional
TotalNumberofReads
column. This column, which specifies the number of reads, is normally generated during data import by the
SAM Input Engine
,
BAM Input Engine
, or
Eland Input Engine
.
The
sam_mus_gse18905_ch1_6s.sas7bdat
and
edf_mus_gse18905_chr1_6s.sas7bdat
data sets were downloaded from
GEO
.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
Refer to the
RPM Scaling
output documentation for detailed descriptions of the output of this process.