The
Create Annotation Analysis Group Variable
process adds a new
variable
named
_AnalysisGroup_
to your
Annotation Data Set
. This variable, which defines analysis groups of markers, can be used as an annotation analysis
group variable
for processes such as
Recode Genotypes
(for collapsing rare variants),
Multiple SNP-Trait Association
, or
P
-Value Combination
. Group size can be set to include a specified number of markers, or to include all markers within a positional window on a
chromosome
. To group by chromosome and position, these variables must be included in the
Input Data Set
.
One input
Annotation Data Set
is needed to run this process. This data set contains information, such as gene identity or chromosomal location, for each of the markers.
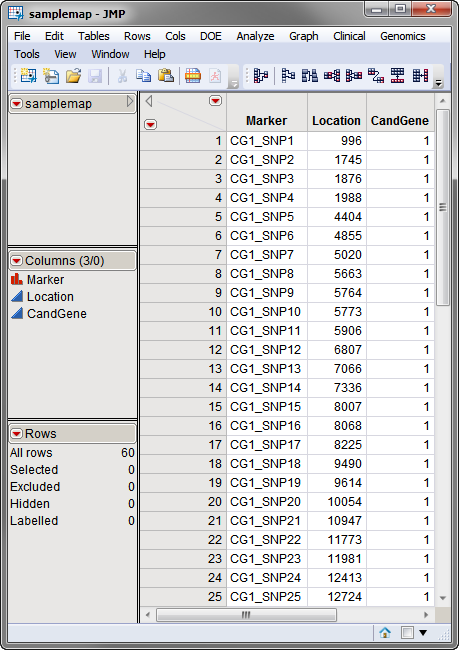
The
annotation data set
used in this example, the
samplemap.sas7bdat
data set, is from
Sample Genetic Marker Data
. This data set was computer generated and includes data on four quantitative
traits
, 60 makers, and two candidate genes. The
samplemap.sas7bdat
annotation data set identifies markers, location, and gene identities for the 60 markers. A portion of this data set is illustrated below
. This data set is a tall data set; each row corresponds to a different marker.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
Output from this process includes one output data set accessed from a
Results
window. Refer to the
Create Annotation Analysis Group Variable
output documentation for detailed descriptions and guides to interpreting your results.