Large data sets are frequently arranged somewhat haphazardly. Individuals and markers are arranged in many different, if not random, orders (this is often true of Affymetrix data sets). Frequently, their placement within the data set is dependent upon their physical locations on the chips rather than other more logical groupings, such as gene function or chromosomal location. In addition, genetic data sets taken from hundreds or thousands of individuals are rarely complete. Often, such data sets contain individuals for whom no information is available at many different markers. Including such individuals in an analysis has the potential to skew the results, so as to render any conclusions suspect.
Subset and Reorder Genetic Data
enables you to perform any combination of one or more of the following steps:
|
•
|
filter out individuals from a
genotype
data set,
|
|
•
|
filter out markers from the genotype and
Annotation Data Set
s simultaneously, and
|
|
•
|
reorder markers in the genotype and
Annotation Data Set
s simultaneously.
|
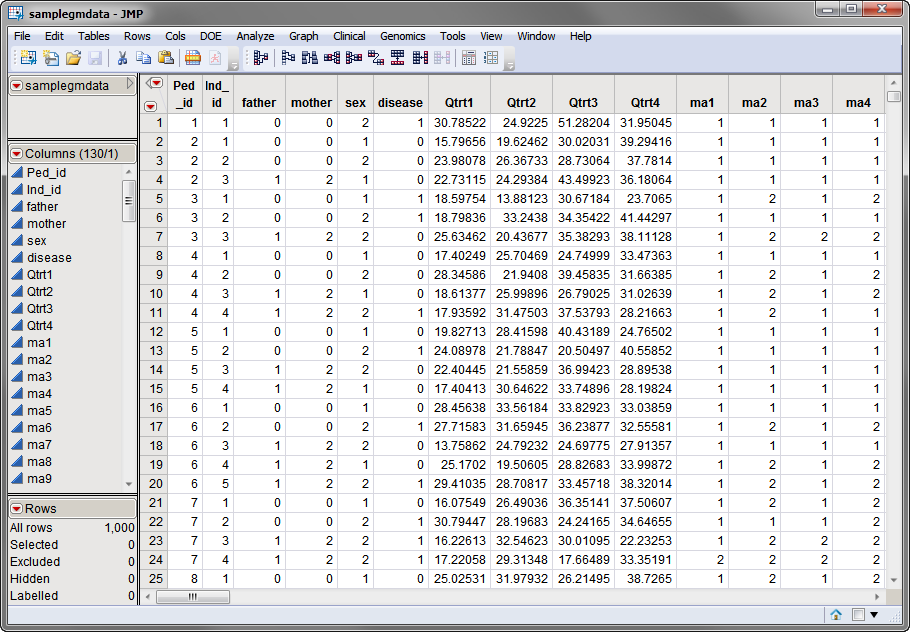
Two data sets are needed for this process. The first, the
Input Data Set
, contains all of the marker data. The sample data set used in the following example, the
samplegmdata
data set, was computer generated as described in
Sample Genetic Marker Data
. It consists of 1000 rows of individuals with 130 columns corresponding to data on these individuals. Marker data is presented in the two-column format for 60 different genotypes. This data set is partially shown below. Note that this is a wide data set; markers are listed in columns, whereas individuals are listed in rows.
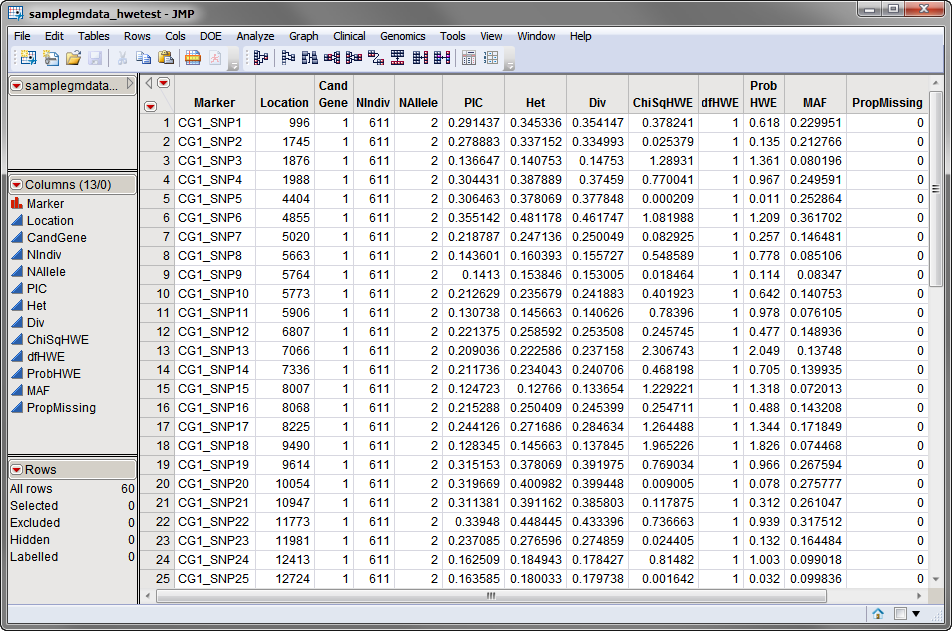
The second data set
is the
Annotation Data Set
. This data set contains information, such as gene identity or chromosomal location, for each of the markers. The
annotation data set
used in this example, the
samplegmdata_hwetest
data set, was generated using the
Marker Properties
process. A portion of this data set is illustrated below. This data set is a tall data set; each row corresponds to a different marker.
Note
: The top-to-bottom order of the rows in the annotation data set matches the left-to-right order of the columns in the input data set. This correspondence is required for this process.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
Output from this process is accessed from a
Results
window. Refer to the
Subset and Reorder Genetic Data
output documentation for detailed descriptions and guides to interpreting your results.