The
Virtual Twins
process fits a
model
to counter-factual data to find a subgroup of rows with enhanced treatment effects using a modification of the procedure of Foster
et al
., (2011)
1
. This process follows the following steps: 1. Fit a forest model to the response. 2. Compute individual treatment effects by scoring actual and counter-factual data 3. Fit a standard
tree
model to the estimated treatment effects.
One
wide
format data set is required to run the
Virtual Twins
process. This data set must contain one column containing the dependent response
variable
, one column containing the treatment variable, and multiple columns to be used as
predictor
variables.
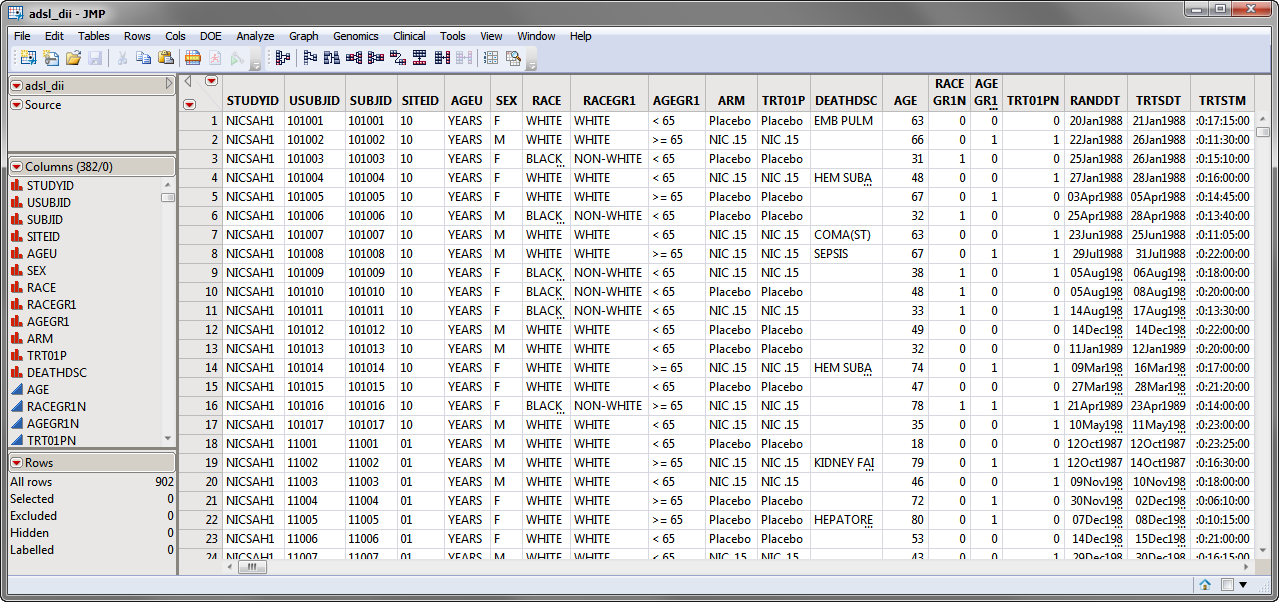
The
adsl_dii.sas7bdat
data set, partially shown below, details results for 902 subjects. Subjects are listed in rows, demographic information, trial details, and findings and results are listed in columns. The
ARM
column lists the treatment variable. The
DEATHFL
column lists the
dependent variable
. The predictor variables are spread across 310 columns.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
Refer to the
Virtual Twins
output documentation for detailed descriptions of the output and guides to interpreting your results.
Foster, JC, JMG Taylor, and SJ Ruberg. 2011.Subgroup identification from randomized clinical trial data.
Statist. Med.
30
: 2867-2880.