Running this process for the
BCSample
sample setting generates the following
Results
window. Refer to the
Build QTL Genotype Probability Data Set
process description for more information.
|
•
|
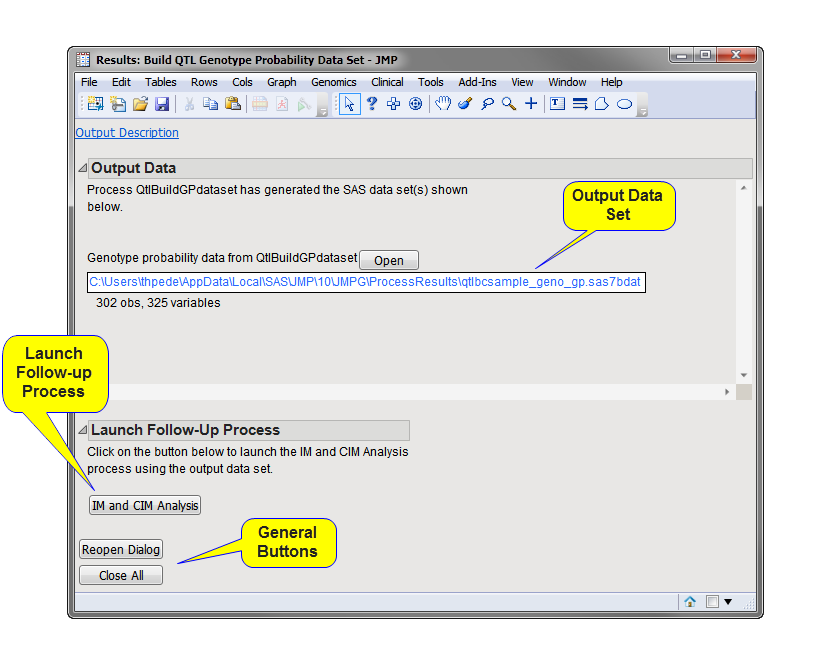
Genotype Probability Output Data Set
: This data set contains the
genotype
probabilities estimated between observed markers along the
genetic distance
map. It is formatted specifically for internal use with the
QTL IM, CIM and MIM Analysis
process, where the probabilities are used in the
Interval Mapping
and
Composite Interval Mapping
algorithms to find significant
QTLs
at testing cM intervals. For crosses with 3 distinct possible genotypes (such as an F2), there will be two columns per
chromosome
and cM interval position, whereas there will be just one column for crosses with only 2 distinct genotypes (for example Backcrosses). The first row contains the chromosome number, the second contains the cM interval, the third contains indicator
variables
to markers (1 indicates marker and 0 inter-marker position).
|
The
qtlbcsample_geno_gp.sas7bdat
output data set lists the probabilities of observing specific QTL genotypes at each one cM interval along the chromosome(s) represented by the markers for each of the 300 individuals listed in the input data set (rows 3 through 302). Row 1 specifies the relevant chromosome, row 2 specifies the interval, and row 3 indicates markers (1 indicates marker and 0 inter-marker position).
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
|
•
|
QTL IM, CIM and MIM Analysis
: Click
|
|
•
|
Click
|