The
Correlation and Principal Variance Component Analysis
process computes correlations between
numeric variables
,
principal components
of the correlation matrix, and an accompanying outlier analysis. It also optionally computes a
variance
components decomposition that helps you determine the major sources of overall variability in your experiment.
One data set is
required
for this process: the
Input Data Set
that contains all of the numeric data to be analyzed. The
drosophilaaging_norm.sas7bdat
data set is a normalized data set derived from the
Drosophila
Aging experiment described in
Drosophila Aging Experimental Data
, and serves as an example. This data set is partially shown below. It has 49 columns and 100 rows. Note that this is a tall data set; each
probe
corresponds to one row whereas each column corresponds to a separate experimental condition.
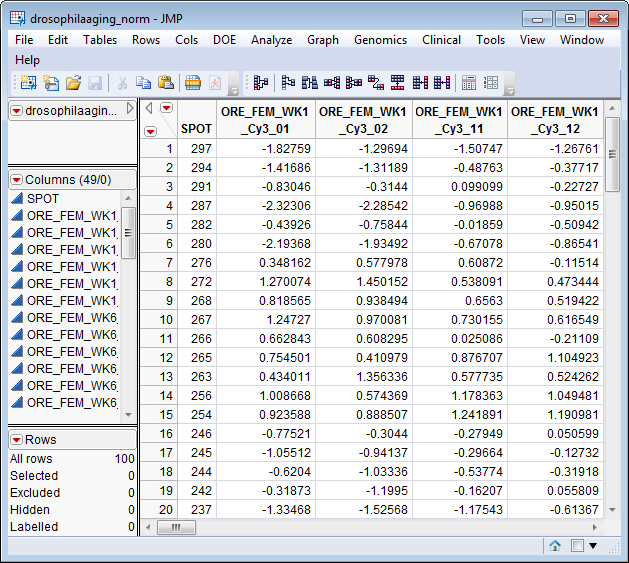
Two data sets are
optional
:
|
•
|
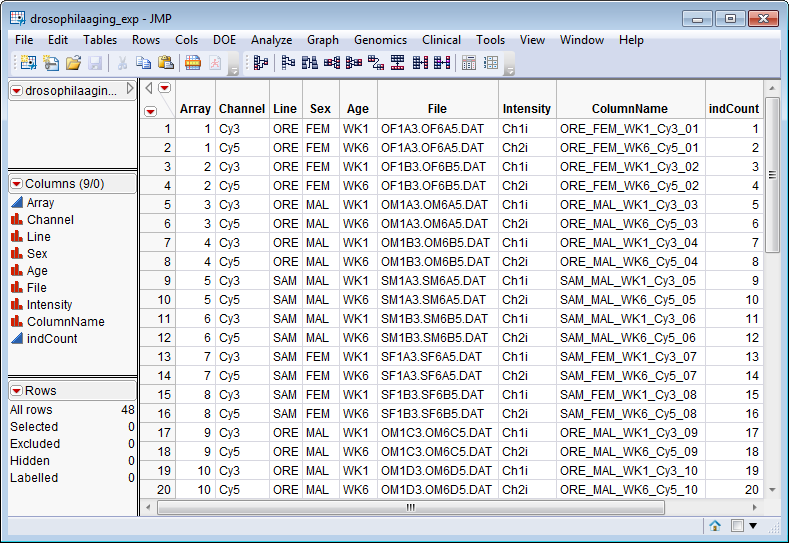
The
Experimental Design Data Set (EDDS)
. The
drosophilaaging_exp.sas7bdat
EDDS, which is used in the example that follows, is shown below. This data set tells how the experiment was performed, providing information about the columns in the input data set. Note that one column in the EDDS must be named
ColumnName
and the values contained in this column must exactly match the column names in the input data set.
|
|
•
|
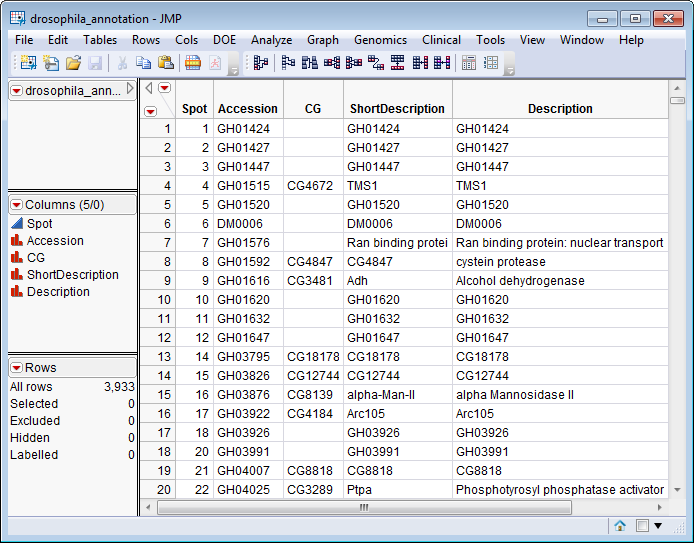
The
Data Set to Use for Filter
. This data set is used to establish filtering criteria for determining those input
observations
to include in the correlation. It must contain at least one merging key
variable
to merge with the input data set. The
drosophila_annotation.sas7bdat
file serves as an example, and is shown below.
|
The example experiment consisted of 24 two-color cDNA
microarrays
, six for each experimental combination of two lines (Oregon and Samarkand), two sexes (Female and Male), and two ages (1 week and 6 weeks). The
Cy3
and
Cy5
dyes were flipped for two of the six replicates for each
genotype
and sex combination. The design is a split-plot design, with
Age
and
Dye
as subplot
factors
, and
Line
and
Sex
as whole-plot factors. A total of 4256 clones were spotted on the arrays, but for this example, we use a subset containing 100 randomly selected genes. Raw data from this experiment was normalized to the
mean
to generate the
drosophilaaging_norm.sas7bdat
data set.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
The output generated by this process is summarized in a Tabbed report. Refer to the
Correlation and Principal Variance Component Analysis
output documentation for detailed descriptions and guides to interpreting your results.