This process performs a meta-analysis of genome-wide
association
studies by combining
P-values
or effects for a particular test from multiple studies and calculating a combined
p
-value or effect.
The first and second methods weight effects, such as
regression
coefficients or
log odds
ratios, from the studies by the inverse
variance
, calculated as the inverse square of the
Standard Error Variable
, and calculate a
z
-score based on the weighted combined effect and its
standard error
.
|
•
|
When the
random effects
model
is selected, the weights include an estimate of the between-study variance (DerSimonian and Laird, 1986).
|
|
•
|
The fixed effect model assumes that this variance is 0. When either inverse variance method is selected, a
forest plot
is displayed and also heterogeneity statistics are included in the output to indicate which model is appropriate.
|
The third method uses
p
-values from the studies, converts them to
z
-scores and then combines the
z
-scores signed by the selected Effect Variable and weighted by the square root of the
sample size
(Stouffer
et al
., 1949).
Note
:
Variable
on the
General
tab can be selected for the first specified study, and if any other study uses different variable names, the names for all studies after the first must be specified on the
Other Variable Names
tab.
One data set containing
p-values
, effects, or both, for each of the studies to be analyzed is required to run this process. All of the data sets must be located in the same folder.
You must specify the variables to be included in the analysis. Variables for the first specified study are selected on the
General
tab. Variable names in the additional studies are assumed to be the same. However, if any other study uses variable names that differ from those in the first study, you can specify these additional names on the
Other Variable Names
tab.
For example, the ID, effect, and
p
-value variables are named
SNP
,
BETA
, and
NegLog10(PValue)
, respectively, in both the
study1.sas7bdat
and
study2.sas7bdat
data sets shown below. The variables can be specified on the
General
tab.
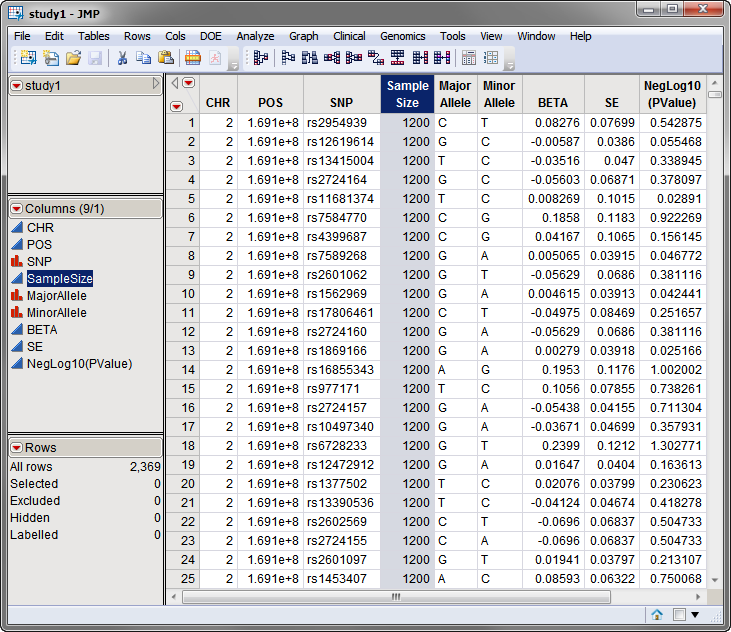
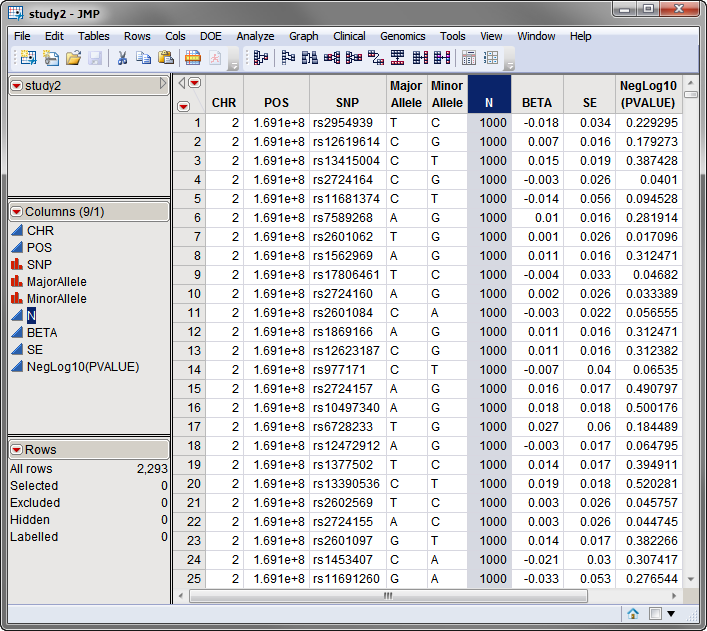
The
Sample Size
variable (highlighted in the figures above) is named differently in the two data sets. The sample size variable name for study1 (
SampleSize
) is specified in the
Sample Size Variable
field on the
General
tab, whereas the sample size variable name for study2 is specified in the
Other Sample Size Variables
field on the
Other Variable Names
tab.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
The output generated by this process is summarized in a Tabbed report. Refer to the
GWAS Meta-Analysis
output documentation for detailed descriptions and guides to interpreting your results.