This process creates a data set containing columns of expanded
genotypes
for
simple-sequence repeats
(SSRs) or other multiallelic markers. The output data set contains one column per
allele
at each marker, with either dominant coding indicating the presence of that allele in the marker or additive coding indicating the number of copies of that allele the genotype comprises. An updated
annotation data set
is created as well, with one row per marker allele for all alleles that are included in the genotype data set.
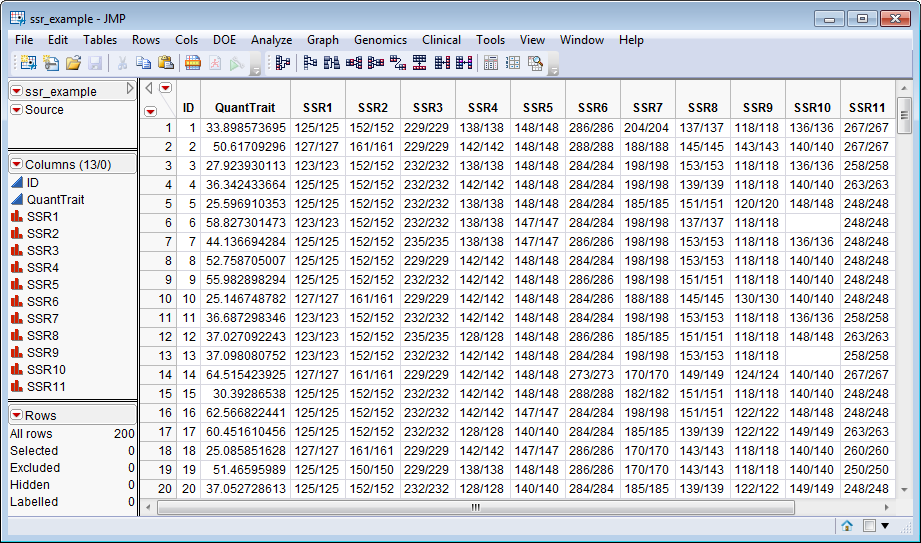
One SAS
Input Data Set
containing multiallelic genotype data is
required
by this process. The
ssr_example.sas7bdat
data set serves as an example and is shown below. It is a
wide
data set, containing 13 columns (a sample identifier, a measure of the quantitative
trait
, and 11
marker variables
) and 200 rows (corresponding to samples).
An
Annotation Data Set
is
optional
.
An annotation data set contains information, such as gene identity or chromosomal location, for each of the markers. Annotation data sets are
tall
data sets; each row corresponds to a different marker.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
Output from this process is accessed from a
Results
window. Refer to the
Expand Multiallelic Genotypes
output documentation for detailed descriptions and guides to interpreting your results.