Many statistical
hypothesis testing
methods produce
p-values
. A
p
-value is the probability of observing that a
test statistic
is as or more extreme than the one computed from the data assuming that the relevant
null hypothesis
is true. The null hypothesis usually represents no
association
or relationship, and so, smaller
p
-values represent more evidence that the null is not true. The scale of evidence here is based on a type of probabilistic
modus tollens
, or argument by contradiction. A
p
-value is very often misinterpreted as the probability of the null hypothesis or as the probability of a false positive.
The
JMP Genomics Browser
can adjust columns of
p
-values for multiple testing as well as plot adjusted and transformed
p
-values using chromosomal positions. Results can be journaled by a group such as
chromosome
or candidate gene. The output data set also contains
variables
indicating significance and number of consecutive significant
p
-values according to the specified
alpha
level. Finally, a graphic representation of the gene can be overlaid onto the
p
-value plot to help you explore the significance and potential mechanism of differential
expression
.
One
Input Data Set
, containing the
p
-values of an arbitrary set of features (for example, genes,
probesets
,
exons
, or markers) is
required
for this process. The
huex_1_mn_trimmed_bew_iqr_amr.sas7bdat
data set serves as an example (
containing a subset of Affymetrix human exon data, available in the JMP Genomics
Sample Data\Copy Number
folder)
, and is partially shown.
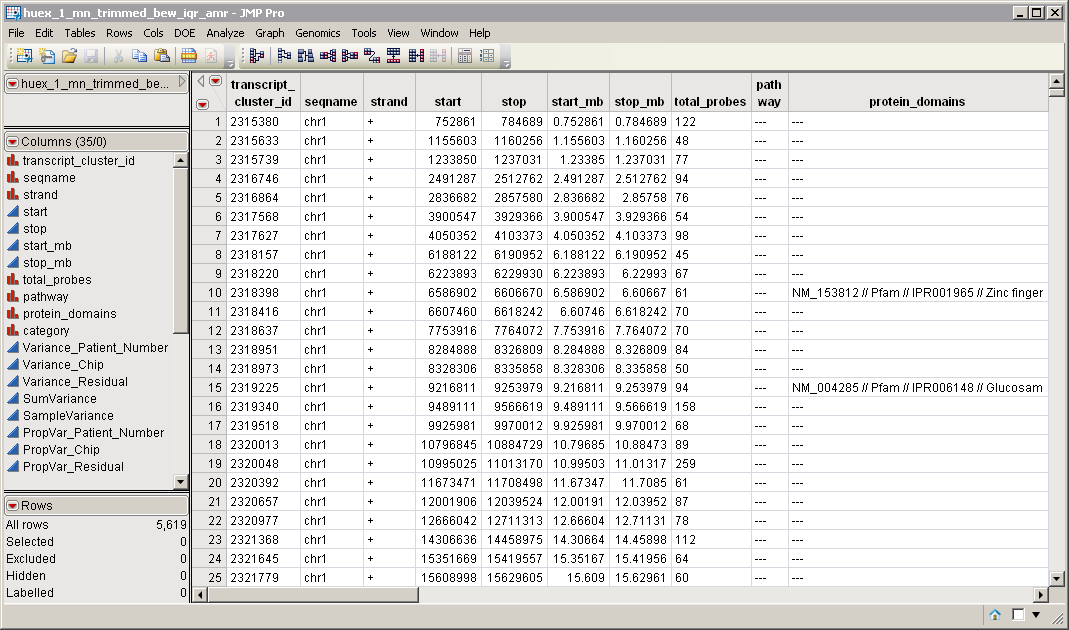
The input data set contains information about each probeset as well as expression values and other data for each gene. The
-log
10
p
-values associated with each
probeset
are listed in the second to the last column (
NLP_T3_Tissue_Type
). Note that this is a tall data set; experimental conditions are listed in columns, whereas the individual genes are listed in rows.
The following files are
optional
:
|
•
|
The
Annotation Data Set
. This data set contains information, such as gene identity or chromosomal location, for each of the markers or genes. This data set is a tall data set; each row corresponds to a different marker.
|
|
•
|
The
chromosome color theme settings file
. This file is a SAS settings (
.sas
) file, generated from a text file using the
Chromosome Color Theme
process. This
settings file
defines the colors used to illustrate individual cytobands on a chromosome plot.
|
|
•
|
The
tracks settings file
. This file is a SAS settings (
.sas
) file, generated from a text file using the
Track Gene Text
process. This settings file defines a track for a set of genes, and is used to embellish the
p
-value plot with depictions of genes.
|
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
Refer to the
JMP Genomics Browser
output documentation for detailed descriptions and guides to interpreting your results.