K-Means clustering
is a standard technique for partitioning data into groups with similar members.
The
K-Means Clustering
process creates optimally separated groups of
observations
(rows) of a SAS data set using one of several methods. A set of points called cluster seeds is selected as a first guess of the
means
of the clusters. Each observation is assigned to the nearest seed to form temporary clusters. The seeds are then replaced by the means of the temporary clusters, and the process is repeated until no further changes occur in the clusters.
You might wish to run
Data Standardize
before doing the
clustering
to ensure that the columns are all comparable.
One data set is required to run the
K-Means Clustering
process. This data set must be in a rectangular format and contain the
variables
(columns) whose observations (rows) are to be clustered.
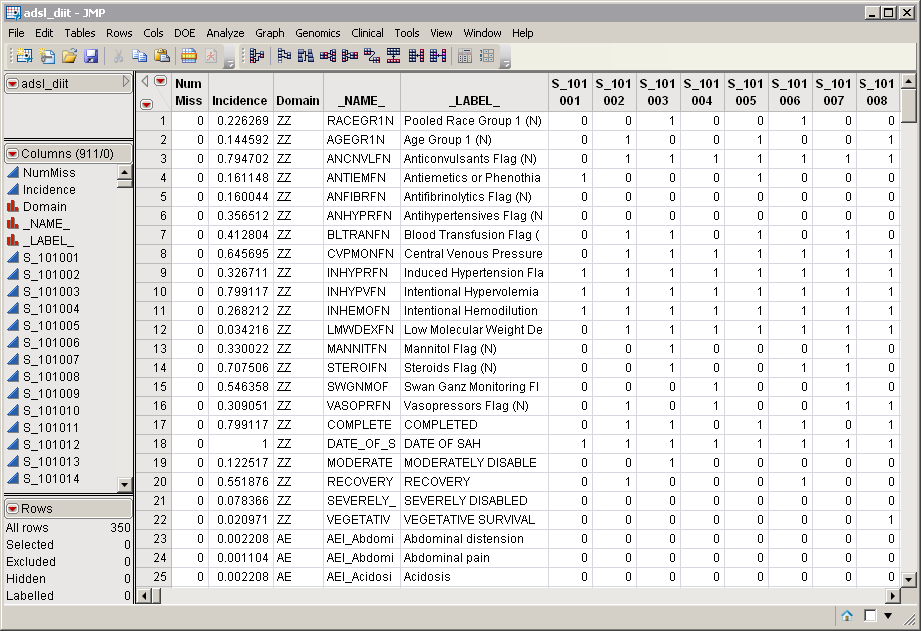
The
adsl_diit.sas7bdat
data set, shown below, was generated from the included
Nicardipine
data set. Patients are listed in columns, and domain data are listed in rows. There are 911 columns for 906 patients and 318 rows listing events.
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
The output generated by this process is summarized in a Tabbed report. Refer to the
K-Means Clustering
output documentation for detailed descriptions and guides to interpreting your results.