Most of the processes in JMP Genomics assume that the input SAS data set has a particular data structure. JMP Genomics distinguishes between
tall
and
wide
SAS data sets. A
tall
SAS data set has samples as columns, and molecular entity (such as marker, gene, clone, protein, or metabolite) as rows. A
wide
SAS data set is the transpose of a
tall
data set, having the samples as rows and molecular entity as columns. When specifying the input SAS data set for a process, it is important to know the required form. Most of the processes associated with genetic analyses require a
wide
structure, whereas most of those for
microarray
and proteomics analyses use a
tall
structure.
The
Transpose Wide to Tall
process transposes a SAS data set in
wide
format into a SAS data set in
tall
format, and generates an accompanying experimental design data set.
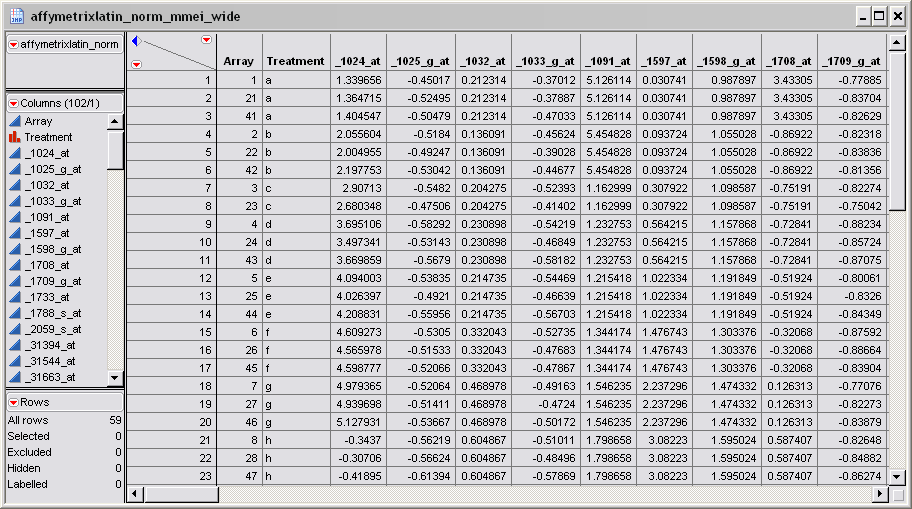
Only the wide
Input Data Set
to be transposed is
required
for transposing from the
wide
format to the
tall
format. The
affymetrixlatin_norm_mmei_wide.sas7bdat
data set (found in the \
LifeSciences\Sample Data\Microarray\Affymetrix Latin Square
directory included with JMP Genomics, and described in
Affymetrix Latin Square Data
) is shown
below
. This is a wide data set with
probesets
listed in 100 data columns and individual arrays listed in the 59 data rows.
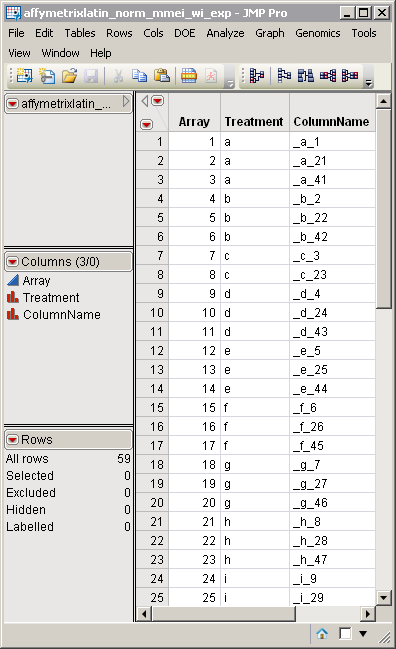
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
The tall SAS data set and the
Experimental Design Data Set (EDDS)
generated by this process are listed in a
Results
dialog
that is displayed in a new window.
|
|
Click
to view the
affymetrixlatin_norm_mmei_wi_tal.sas7bdat
output tall data set.
|
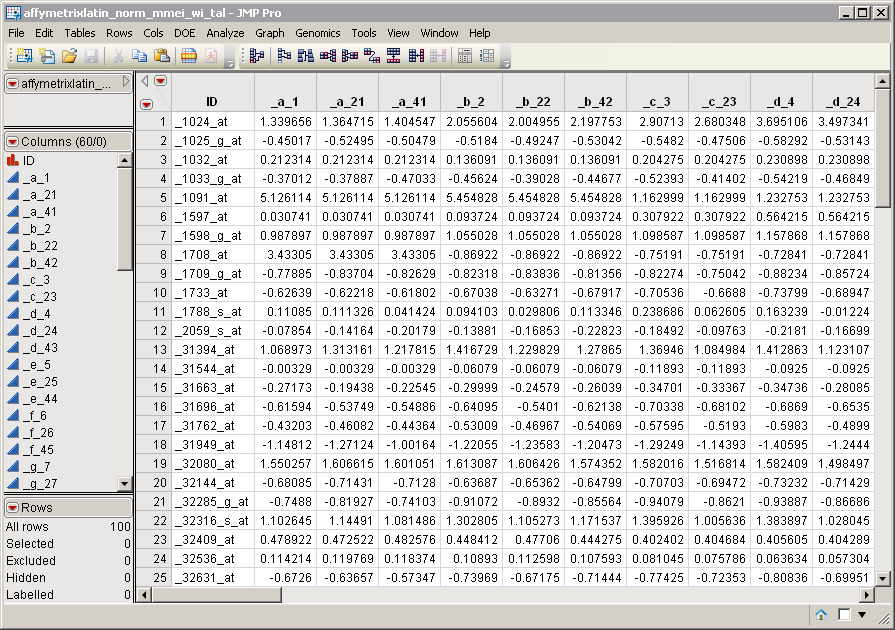
The data has been transposed; there are now 59 data columns and 100 data rows. In addition, the
_tal
suffix has been appended to the transposed filename.
|
|
Click
to view the
affymetrixlatin_norm_mmei_wi_exp.sas7bdat
output EDDS.
|