The
process rearranges the order of the columns in the input data set. This feature is especially useful for reorganizing a data set formed by merging two or more disparate data sets.
Tip:
You can also reorder
variables
by opening the table in JMP and using the
Cols > Reorder Columns
command.
|
•
|
The
Input Data Set
containing the columns to be reordered.
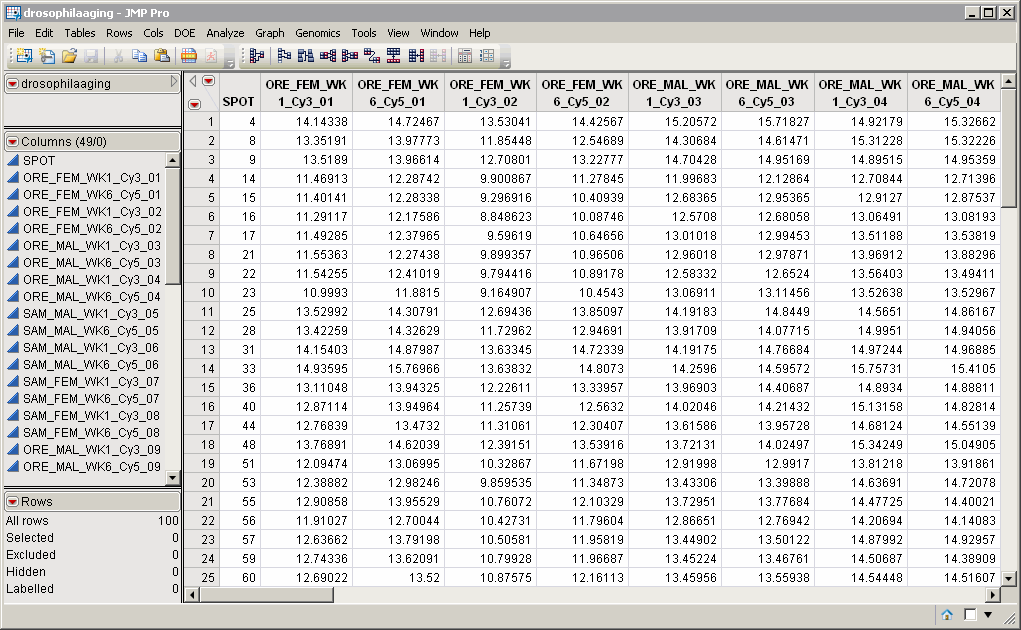
The
drosophilaaging.sas7bdat
data set (located in the
\LifeSciences\Sample Data\Microarray\Scanalyze Drosophila
directory included with JMP Genomics, associated with the
Drosophila
aging experiment of Jin et al. (2001) described in
Drosophila Aging Experimental Data
) serves as an example,
and is shown
below
.
|
|
•
|
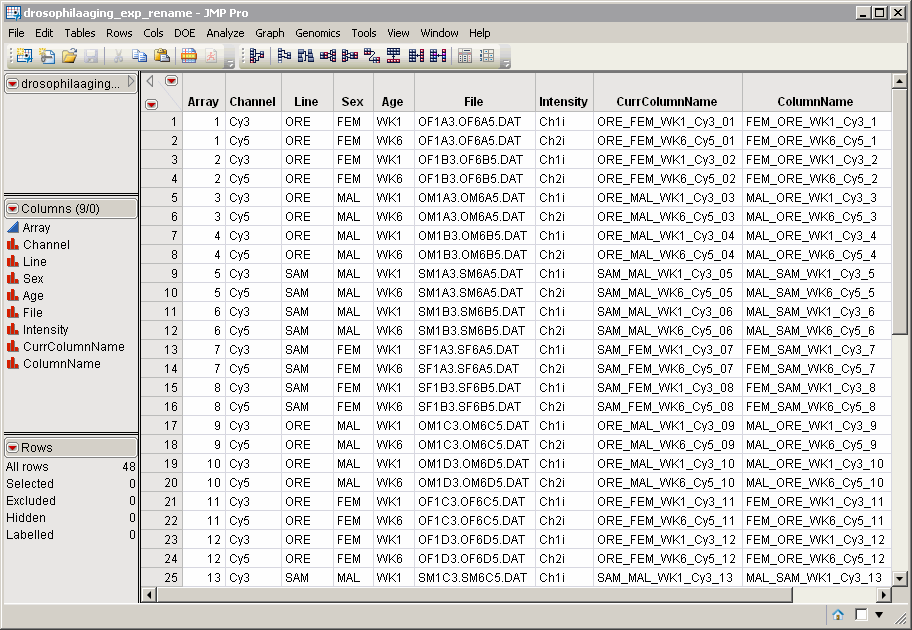
A modified
Experimental Design Data Set (EDDS)
(also known as the
column order data set
). This required data set tells how the experiment was performed, providing information about the columns of the primary experimental data. Before running this process, however, you must modify the EDDS so that the order of the values in the
ColumnName
variable matches the desired order of the columns in the reordered input data set. The standard
drosophilaaging_exp.sas7bdat
EDDS (located in the
\LifeSciences\Sample Data\Microarray\Scanalyze Drosophila
directory included with JMP Genomics, associated with the
Drosophila
aging experiment of Jin, et al. (2001) described in
Drosophila Aging Experimental Data
) was modified and renamed. The modified
drosophilaaging_exp_rename.sas7bdat
column order data set is shown
below
.
|
For detailed information about the files and data sets used or created by JMP Life Sciences software, see
Files and Data Sets
.
|
|
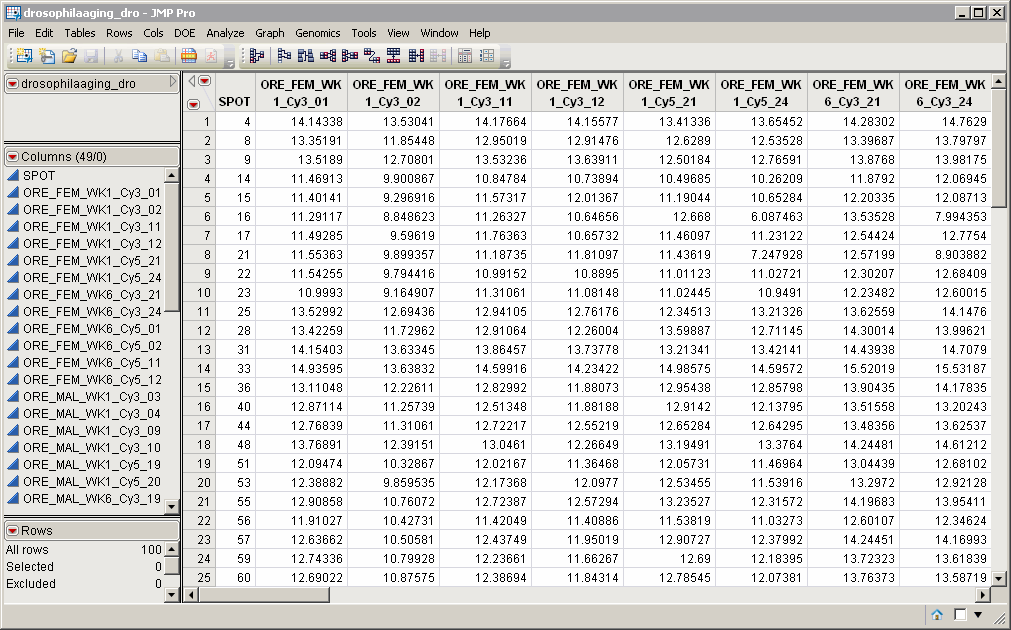
The order of the columns in the output data set has changed to match the new order given in the
drosophilaaging_exp_sorted.sas7bdat
column order data set.