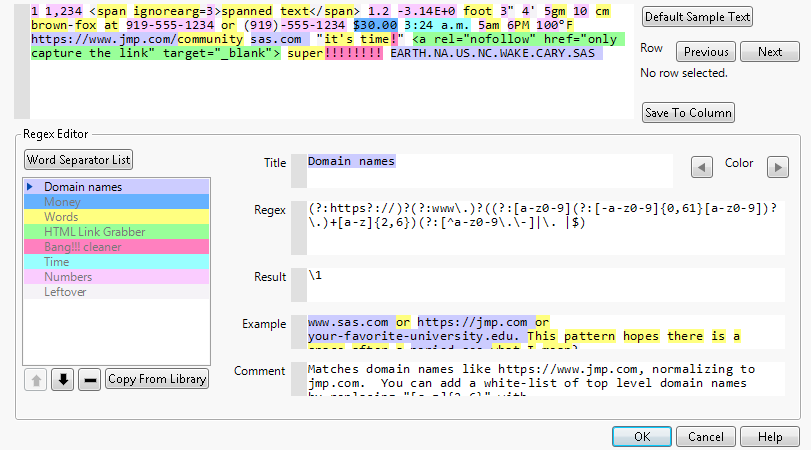
When you select the Customize Regex option, the Text Explorer Regular Expression Editor appears. Use this window to parse text documents using a wide variety of built-in regular expressions, such as phone numbers, times, or monetary values. You can also create your own regular expression definitions.
|
•
|
Click the Previous and Next row buttons to populate the script editor box with text from your own data. This enables you to see how a given row of text data is parsed.
|
|
•
|
Click the Save to Column button to save a new column to the data table that contains the result of the regular expression tokenization. For more information about specifying the result of the regular expression, see Editing the Regular Expressions.
|
Note: The Save to Column button uses only the regular expression to match text. The following settings are not used: stop words, recodes, stemming, phrases, or minimum and maximum characters per word to modify the output of the regular expression.
To add a regular expression to be used in tokenization, click Copy From Library. The Regex Library Selections window appears. This window contains all the built-in regular expressions as well as any recently modified regular expressions that you created in previous instances of the Regular Expression Editor. Built-in regular expressions are labeled. Custom regular expressions that are saved in your library are labeled with the name that you specified. Only the most recent expression for a given name is stored in the Regex Library. Use the Delete Selected Item button to remove a custom regular expression from the Regex Library. The Regex Library for each user is stored as a JSL file in a directory called TextExplorer. The location of this directory is based on your computer’s operating system, as follows:
|
•
|
Windows: "C:/Users/<username>/AppData/Roaming/SAS/JMP/TextExplorer/"
|
|
•
|
Macintosh: "/Users/<username>/Library/Application Support/JMP/TextExplorer/"
|
|
1.
|
Click Copy From Library.
|
|
3.
|
Click OK.
|
Tip: When editing the Regex definition field, it is helpful to have the Log window open and visible. Some error messages appear only in the Log window. To open the Log window, select View > Log. There are many Internet resources available for troubleshooting regular expressions, such as www.regexr.com.
The Word Separator List button enables you to specify a list of characters that occur between words in the tokenization process. The between-word characters cannot begin a word, but they can appear inside a word if one of the regular expressions allows it. You can add or remove characters from the list in the window that appears when you click the button. By default, the only character in the list is a whitespace character. In the Separator Characters window, click the Reset button to undo any modifications to the list of separator characters. Modifications to the list of separator characters are applied only to the current regular expression tokenization.
|
–
|
|
–
|
|
3.
|
Click the Save to Column button to save to the data table a new column that contains the results of the regular expression tokenization. The new column is a character column with the same name as the text column specified in the Text Explorer launch window; a number is appended to the name so that the column names are unique.
After you click OK in the Text Explorer Regular Expression Editor window, the following events occur:
Caution: The custom Regex Library is saved only when you click OK and there are customized regular expressions. The most recently saved regular expressions will be available next time. Use unique names to keep additional regular expressions in the Regex Library. To ensure that a regular expression is available later, you can save a script from the Text Explorer report window.