|
•
|
For a column that contains continuous numeric data, use the Distribution property to select a distribution type to fit to the column. This distribution is used in the Distribution platform and is used in the Process Capability platform under certain conditions. See Distribution and Process Capability Distribution.
When you obtain a Distribution report (by selecting Analyze > Distribution) for the column, JMP automatically estimates a fit using the specified distribution. A curve representing the fitted distribution is superimposed on the histogram.
|
•
|
|
•
|
If the custom boundary files reside in an alternate location, then you must specify the Map Role property in the -Name file and in the data table that you are analyzing.
|
|
1.
|
Right-click on the column containing the boundaries and select Column Properties > Map Role.
|
|
2.
|
Select Shape Name Definition.
|
|
3.
|
Click OK.
|
|
1.
|
Right-click on the column containing the boundaries and select Column Properties > Map Role.
|
|
2.
|
Select Shape Name Use.
|
|
3.
|
Next to Map name data table, click
|
|
4.
|
Next to Shape definition column, enter the name of the column in the map data table whose values match those in the selected column.
|
|
5.
|
Click OK.
|
|
2.
|
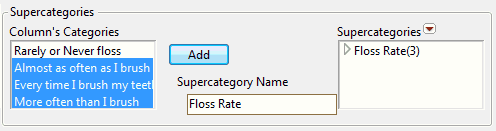
Select Column Properties > Supercategories.
|
|
5.
|
Click Add to create the supercategory.
|
|
6.
|
From the Supercategories red triangle menu, select from the following options:
|
|
–
|
Options > Hide: Hides data in the selected supercategory from reports and graphs.
|
|
–
|
Add All: Creates a supercategory from all of the categories in the column.
|
|
–
|
Add Mean and Add Std Dev: Calculate statistics for value scores. See the Consumer Research book for more information.
|
|
7.
|
Click OK to add the property to the column.
|
Figure 5.5 Example Supercategories Configuration
The term multiple response refers to the situation where the cells in a column contain more than one response value. For example, many cells in the Brush Delimited column in the Consumer Preferences.jmp sample data table contain multiple values. For example, row 6 contains “Wake, After Meal, Before Sleep”.
Add the Multiple Response column property if you want to specify a delimiter other than the comma. Otherwise, change the column’s modeling type to Multiple Response in the Column Info window. See About Modeling Types for details about the Multiple Response modeling type.
Figure 5.6 Multiple Response Configuration Window
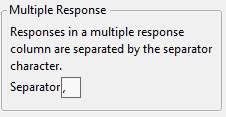
Note: You can use the Multiple Response property in the Categorical platform. See Multiple Response in the Consumer Research book for details. You can also use this property in the Data Filter. See The Data Filter in JMP Reports. If the delimiter is a comma, consider using the Multiple Response modeling type instead.
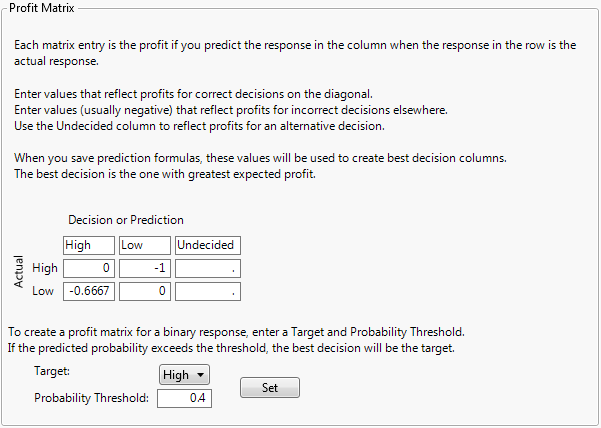
When you select Column Properties > Profit Matrix, a matrix template appears, with a row and column for each value in the selected column. The Actual levels are shown as rows and the predicted levels are shown as columns. Correct decisions are those on the diagonal, where the predicted level equals the actual level.
Enters values into the profit matrix template that reflect your specifications for Target and Probability Threshold. For details, see Probability Threshold Calculations.
Denote the threshold probability by t. When you click Set, the entries in the profit matrix are assigned as follows:
|
•
|
-t/(1 - t) for a prediction of the non-target level when the actual value is the target level
|
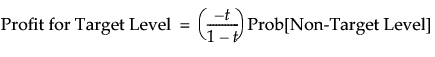
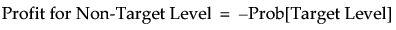
|
•
|
Profit for <level>: For each level of the response, a column gives the expected profit for classifying each observation into that level.
|
|
•
|
Most Profitable Prediction for <column name>: For each observation, gives the level of the response with the highest expected profit.
|
|
•
|
Expected Profit for <column name>: For each observation, gives the expected profit for the classification defined by the Most Profitable Prediction column.
|
|
•
|
Actual Profit for <column name>: For each observation, gives the actual profit for classifying that observation into the level specified by the Most Profitable Prediction column.
|
See Example of a Profit Matrix for More Than Two Levels. For an example of using a profit matrix in modeling, see Decision Matrix Report in the Predictive and Specialized Modeling book.
The example below (Figure 5.7) shows a profit matrix for the Airline column in the Travel Costs.jmp sample data table.
Figure 5.7 Example of Profit Matrix Window
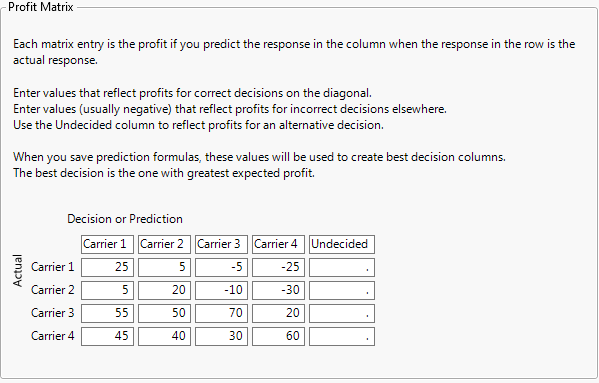
To see how the values in this profit matrix were assigned, consider a travel agency that uses four airlines, Carrier 1 to Carrier 4, to service its customers. For each ticket sold, the agency realizes a profit that depends on the carrier selected by the customer. When the agency recommends, or predicts, a carrier, it reserves a ticket for a small fee. If the customer decides to use the predicted carrier, the agency profits by a certain amount less the reservation fee. However, if the customer decides to take a different carrier, the agency loses the reservation fee and must pay another reservation fee. The agency’s profit is lower due to the incorrect prediction.
The sample data table Liver Cancer.jmp gives disease Severity ratings for 136 patients. You are interested in modeling Severity using the predictors given in the columns from BMI to Jaundice. The usual prediction formulas for a model classify a patient into the Severity level that is most probable. However, classifying a patient as having Low severity when in actuality the patient’s severity is High is a more costly error than classifying a patient as having High severity when in actuality the patient’s severity is Low. As a result, you want to assign a higher cost to misclassifying a patient as Low, when the patient’s severity is actually high.
You can assign this higher cost by setting a probability threshold. With input from experts, you determine that the following is a good strategy: Classify into the High level of Severity any patient whose predicted probability of being in the High level exceeds 0.4.
|
1.
|
|
2.
|
Select the Severity column and select Cols > Column Info.
|
|
4.
|
Change the Target to High.
|
|
5.
|
Enter 0.4 as the Probability Threshold.
|
|
6.
|
Click Set.
|