In JMP you specify the measurement variables as Y effects and the classification variable as a single X effect. The multivariate fitting platform gives estimates of the means and the covariance matrix for the data, assuming that the covariances are the same for each group. You obtain discriminant information with the Save Discrim option in the popup menu next to the MANOVA platform name. This command saves distances and probabilities as columns in the current data table using the initial E and H matrices.
For a classification variable with k levels, JMP adds k distance columns, k classification probability columns, the predicted classification column, and two columns of other computational information to the current data table.
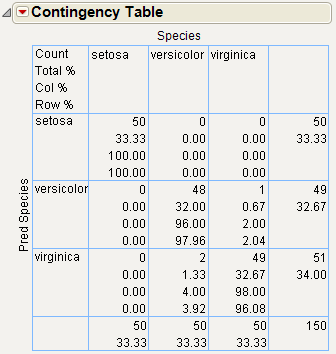
Examine Fisher’s Iris data as found in Mardia, Kent, and Bibby (1979). There are k = 3 levels of species and four measures on each sample.
|
1.
|
|
2.
|
Select Analyze > Fit Model.
|
|
3.
|
|
4.
|
|
5.
|
Next to Personality, select Manova.
|
|
6.
|
Click Run.
|
|
7.
|
From the red triangle menu next to Manova Fit, select Save Discrim.
|
The following columns are added to the Iris.jmp sample data table:
|
1.
|
|
2.
|
|
3.
|
|
4.
|
Click OK.
|