The data in the Diabetes.jmp sample data table consist of measurements on 442 diabetics. The response of interest is Y, disease progression measured one year after a baseline measure was taken. Ten variables thought to be related to disease progression are also measured at baseline. This example shows how to develop a predictive model using generalized regression techniques.
|
1.
|
|
2.
|
Select Analyze > Fit Model.
|
|
3.
|
|
4.
|
This adds all terms up to degree 2 (the default in the Degree box) to the model.
|
5.
|
|
6.
|
From the Personality list, select Generalized Regression.
|
|
7.
|
Click Run.
|
|
8.
|
Click Go.
|
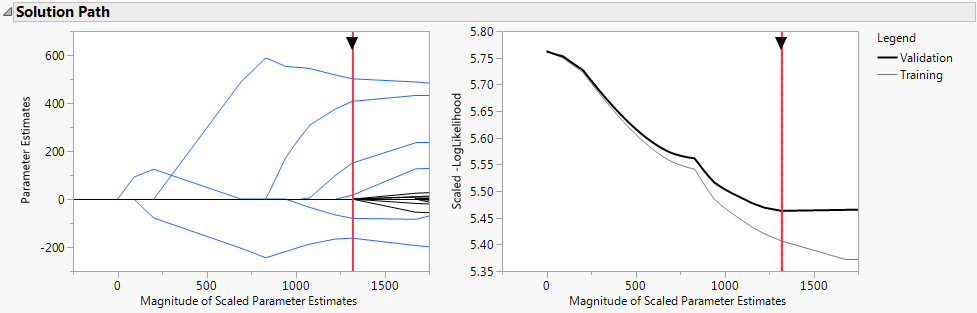
The Solution Path report (Solution Path Plot) shows plots of the parameter estimates and scaled negative log likelihood. The shrinkage increases as the Magnitude of Scaled Parameter Estimates decreases. The estimates at the far right of the plot are the maximum likelihood estimates. A vertical red line indicates those parameter values selected by the validation criterion, in this case, the holdback sample defined by the column Validation.
|
9.
|
Select the option Select Nonzero Terms from the Adaptive Lasso with Validation Column Validation report’s red triangle menu.
|
This option highlights the nonzero terms in the Parameter Estimates for Original Data report (Portion of Parameter Estimates for Original Predictors Report) and their paths in the Solution Path plot. The corresponding columns in the data table are also selected. Note that only 6 of the 55 parameter estimates are nonzero. Also note that the scale parameter for the normal distribution (sigma) is estimated and shown in the last line of the Parameter Estimates for Original Data report.

To save the prediction formula, select Save Columns > Save Prediction Formula from the red triangle menu for the Adaptive Lasso with Validation Column Validation report.
Launch the Generalized Regression personality by selecting Analyze > Fit Model, entering one or more columns for Y, and selecting Generalized Regression from the Personality menu (Fit Model Launch Window with Generalized Regression Selected).
For details about aspects of the Fit Model window that are common to all personalities, see the Model Specification section. Details specific to the Generalized Regression personality are presented here.
When you select Generalized Regression from the Personality menu, the Distribution option appears. Here you can specify a distribution for Y. The abbreviation ZI means zero-inflated. The distributions are separated into three categories based on their response: continuous, discrete, and zero-inflated. The options are described below.
Y has a normal distribution with mean μ and standard deviation σ. The normal distribution is symmetric and with a large enough sample size, can approximate a large variety of other distributions using the Central Limit Theorem. The link function for μ is the identity. That is, the mean of Y is expressed as a linear model. In estimating the model parameters, the scale parameter σ is profiled out. It is then replaced by its maximum likelihood estimate (MLE). (Note that the MLE is not the typical unbiased estimator for σ.) See Statistical Details for Distributions.
Y has a Cauchy distribution with location parameter μ and scale parameter σ. The Cauchy distribution has an undefined mean and standard deviation. The median and mode are both μ. Most data do not inherently follow a Cauchy distribution, but it is useful for conducting a robust regression on data that contain a large proportion of outliers (up to 50%). The link function for μ and σ is the identity. See Statistical Details for Distributions.
Y has an exponential distribution with mean parameter μ. The exponential distribution is right-skewed and is often used to model lifetimes or the time between successive events. The link function for μ is the logarithm. See Statistical Details for Distributions.
Y has a gamma distribution with mean parameter μ and dispersion parameter σ. The gamma is a flexible distribution and contains a family of other widely used distributions. For example, the exponential distribution is a special case of the gamma distribution where σ = μ. The Weibull and chi squared distributions can also be derived from the gamma distribution. The link function for μ is the logarithm. See Statistical Details for Distributions.
Y has a beta distribution with mean parameter μ and dispersion parameter σ. The response for the beta is between 0 and 1 (not inclusive) and is often used to model proportions or rates. The link function for μ is the logit. See Statistical Details for Distributions.
Quantile Regression
Y has a binomial distribution with parameters p and n. The response, Y, indicates the total number of successes in n independent trials with a fixed probability, p, for all trials. This distribution allows for the use of a sample size column. If no column is listed, it is assumed that the sample size is one. The link function for p is the logit. When you select Binomial as the Distribution, the response variable must be specified in one of the following ways. See Statistical Details for Distributions.
Y has a beta binomial distribution with the probability of success, p, the number of trails, n, and overdispersion parameter, δ. This distribution is an overdispersed version of the binomial distribution.
Run demoBetaBinomial.jsl in the JMP Samples/Scripts folder to compare a beta binomial distribution with dispersion parameter δ to a binomial distribution with parameters p and n = 20.
The beta binomial distribution requires a sample size greater than one for each observation. Thus, the user must specify a sample size column. To insert a sample size column, specify two continuous columns as Y in this order: the count of the number of successes, and the count of the number of trials. The link function for p is the logit. See Statistical Details for Distributions.
Y has a Poisson distribution with mean λ. The Poisson distribution typically models the number of events in a given interval and is often expressed as count data. The link function for λ is the logarithm. Poisson regression is permitted even if Y assumes non-integer values. See Statistical Details for Distributions.
Y has a negative binomial distribution with mean μ and dispersion parameter σ. The negative binomial distribution typically models the number of successes before a specified number of failures. The negative binomial distribution is also equivalent to the Gamma Poisson distribution under certain conditions. For more details about the connection between negative binomial and Gamma Poisson, see the Distributions chapter in the Basic Analysis book.
Run demoGammaPoisson.jsl in the JMP Samples/Scripts folder to compare a Gamma Poisson distribution with mean λ and dispersion parameter σ to a Poisson distribution with mean λ.
The link function for μ is the logarithm. Negative binomial regression is permitted even if Y assumes non-integer values. See Statistical Details for Distributions.
Y has a zero-inflated binomial distribution with parameters p, n, and zero-inflation parameter π. The response, Y, indicates the total number of successes in n independent trials with a fixed probability, p, for all trials. This distribution allows for the use of a sample size column. If no column is listed, it is assumed that the sample size is one. The link function for p is the logit. See Statistical Details for Distributions.
Y has a beta binomial distribution with the probability of success, p, the number of trails, n, overdispersion parameter, δ, and zero-inflation parameter π. This distribution is an overdispersed version of the ZI binomial distribution. The ZI beta binomial distribution requires a sample size greater than one for each observation. Thus, the user must specify a sample size column. To insert a sample size column, specify two continuous columns as Y in this order: the count of the number of successes, and the count of the number of trials. The link function for p is the logit. See Statistical Details for Distributions.
Y has a zero-inflated Poisson distribution with mean parameter λ and zero-inflation parameter π. The parameter λ is the conditional mean based on the observations coming from the Poisson distribution and not the inflating zeros. The link function for λ is the logarithm. ZI Poisson regression is permitted even if Y assumes no observed zeros or non-integer values. See Statistical Details for Distributions.
Y has a zero-inflated negative binomial with location parameter μ, dispersion parameter σ, and zero-inflation parameter π. The parameter μ is the conditional mean based on the observations coming from the negative binomial distribution and not the inflating zeros. The link function for μ is the logarithm. ZI negative binomial regression is permitted even if Y assumes no observed zeros or non-integer values. See Statistical Details for Distributions.
Y has a zero-inflated gamma distribution with mean parameter μ and zero-inflation parameter π. Many times, we might believe that our nonzero responses are gamma distributed. This is true for insurance claims: claim values are approximately gamma distributed but there are also zeros in the data for policies that do not have any claims. The zero-inflated gamma could handle such data directly without having to split the data into zero and nonzero responses. The parameter μ is the conditional mean based on observations coming from the gamma distribution and not the inflating zeros. The link function for μ is the logarithm. See Statistical Details for Distributions.
Requirements for Y for Distributions gives the Data Types, Modeling Types, and other requirements for Y variables assigned the various distributions.
Details on how these distributions are parameterized are given in Statistical Details for Distributions. Distributions, Parameters, and Link Functions summarizes the details.
|
μ, σ
|
|
|
|
μ, σ
|
|
|
|
|
||
|
μ, σ
|
|
|
|
|
||
|
n, p
|
|
|
|
|
||
|
|
||
|
μ, σ
|
|
|
|
|
||
|
|
||
|
λ, π (zero-inflation)
|
|
|
|
μ, σ, π (zero-inflation)
|
|
|
|
μ, σ, π (zero-inflation)
|
|
After selecting an appropriate Distribution, click Run. The Generalized Regression Model Launch panel opens.
|
•
|
|
•
|
|
•
|
Computes parameter estimates using ridge regression. This technique applies an l2 penalty. See Statistical Details for Estimation Methods.
Computes parameter estimates by applying an l1 penalty. Due to the l1 penalty, some coefficients can be estimated as zero. Thus, variable selection is performed as part of the fitting procedure. In the ordinary Lasso, all coefficients are equally penalized. See Statistical Details for Estimation Methods.
Computes parameter estimates by penalizing a weighted sum of the absolute values of the regression coefficients. The weights in the l1 penalty are determined by the data in such as way as to guarantee the oracle property (Zou, 2006). This option uses the MLEs to weight the l1 penalty. MLEs cannot be computed when the number of predictors exceeds the number of observations or when there are strict linear dependencies among the predictors. If MLEs for the regression parameters cannot be computed, a generalized inverse solution or a ridge solution is used for the l1 penalty weights. See Statistical Details for Estimation Methods.
Computes parameter estimates by applying both an l1 penalty and an l2 penalty. The l1 penalty ensures that variable selection is performed. The l2 penalty improves predictive ability by shrinking the coefficients as ridge does. See Statistical Details for Estimation Methods.
Computes parameter estimates using an adaptive l1 penalty as well as an l2 penalty. This option uses the MLEs to weight the l1 penalty. MLEs cannot be computed when the number of predictors exceeds the number of observations or when there are strict linear dependencies among the predictors. If MLEs for the regression parameters cannot be computed, a generalized inverse solution or a ridge solution is used for the l1 penalty weights. You can set a value for the Elastic Net Alpha in the Advanced Controls panel. See Statistical Details for Estimation Methods.
The solution paths for the Lasso and Ridge Estimation Methods depend on a single tuning parameter. The solution path for the Elastic Net depends on a tuning parameter for the penalty on the likelihood as well as the Elastic Net Alpha. The penalty on the likelihood for the Elastic Net is a weighted sum of the penalties associated with the Lasso and Ridge Estimation Methods. The Elastic Net Alpha determines the weights of these two penalties. See Statistical Details for Estimation Methods and Statistical Details for Advanced Controls.
The grid of tuning parameter values ranges from zero, in most cases, to the smallest value for which all of the non-intercept terms are zero. Define the smallest value of the tuning parameter for which all non-intercept terms are zero to be its upper bound. The lower bound for the tuning parameter is zero except in the following two cases where it is set to 0.01:
Requires lower-order effects to enter the model before their related higher order effects. In most cases, this means that X2 is not in the model unless X is in the model. For estimation methods other than Forward Selection, however, it is possible for X2 to enter the model and X to leave the model in the same step. If the data table contains a DOE script, this option is enabled, but it is off by default.
Sets the α parameter for the Elastic Net. This α parameter determines the mix of the l1 and l2 penalty tuning parameters in estimating the Elastic Net coefficients. The default value is α = 0.9, which sets the coefficient on the l1 penalty to 0.9 and the coefficient on the l2 penalty to 0.1. This option is available only when Elastic Net is selected as the Estimation Method. See Statistical Details for Estimation Methods.
Provides options for choosing the distribution of the grid scale. You can choose between a linear, square root, or log scale. Grid points equal in number to the specified Number of Grid Points are distributed according to the selected scale between the lower and upper bounds of the tuning parameter. See Statistical Details for Advanced Controls.
|
‒
|
|
‒
|
In turn, each fold is used as a validation set. A model is fit to the observations not in the fold. The LogLikelihood based on that model is calculated for the observations in the fold, providing a validation LogLikelihood.
|
|
‒
|
The mean of the validation LogLikelihoods for the k folds is calculated. This value serves as a validation LogLikelihood for the value of the tuning parameter.
|
The value of the tuning parameter that has the maximum validation LogLikelihood is used to construct the final solution. To obtain the final model, all k models derived for the optimal value of the tuning parameter are fit to the entire data set. Of these, the model that has the highest LogLikelihood is selected as the final model. The training set used for that final model is designated as the Training set and the holdout fold for that model is the Validation set. These are the Training and Validations sets used in plots and results in the report for the final solution.
Minimizes the Bayesian Information Criterion (BIC) over the solution path. For more details, see Likelihood, AICc, and BIC in Statistical Details.
Minimizes the corrected Akaike Information Criterion (AICc) over the solution path. AICc is the default setting for Validation Method. For more details, see Likelihood, AICc, and BIC in Statistical Details.
When you click Go, a report opens. The title of the report specifies the fitting and validation methods that you selected. You can return to the Model Launch window to perform additional analyses and choose other estimation and validation methods.