The Self-Organizing Maps (SOMs) technique was developed by Teuvo Kohonen (1989) and further extended by a number of other neural network enthusiasts and statisticians. The original SOM was cast as a learning process, like the original neural net algorithms, but the version implemented here is done in a much more straightforward way as a simple variation on k-means clustering. In the SOM literature, this would be called a batch algorithm using a locally weighted linear smoother.
The goal of a SOM is not only to form clusters, but form them in a particular layout on a cluster grid, such that points in clusters that are near each other in the SOM grid are also near each other in multivariate space. In classical k-means clustering, the structure of the clusters is arbitrary, but in SOMs the clusters have the grid structure. This grid structure helps interpret the clusters in two dimensions: clusters that are close are more similar than distant clusters.
To create a Self Organizing Map, select that option on the Method menu of the Iterative Clustering Control Panel (Iterative Clustering Control Panel). After selecting Self Organizing Map, the control panel looks like Self Organizing Map Control Panel.
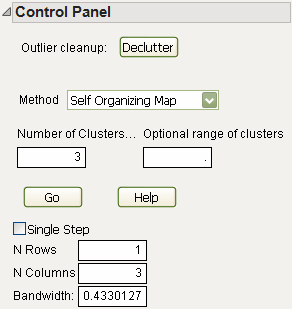
Some of the options on the panel are described in K-Means Control Panel. The other options are described below:
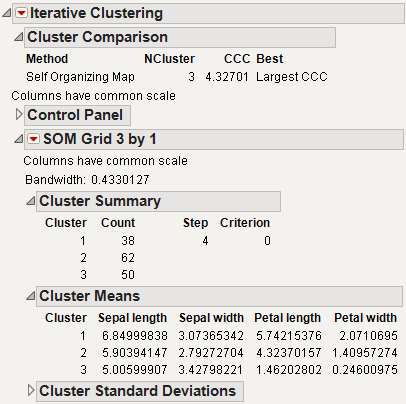
The Cluster Comparison report gives fit statistics to compare different numbers of clusters. For KMeans Clustering and Self Organizing Maps, the fit statistic is CCC (Cubic Clustering Criterion). For Normal Mixtures, the fit statistic is BIC or AICc. Robust Normal Mixtures does not provide a fit statistic.
|
•
|
The cluster assignment proceeds as with k-means, with each point assigned to the cluster closest to it.
|
|
•
|
The means are estimated for each cluster as in k-means. JMP then uses these means to set up a weighted regression with each variable as the response in the regression, and the SOM grid coordinates as the regressors. The weighting function uses a ‘kernel’ function that gives large weight to the cluster whose center is being estimated, with smaller weights given to clusters farther away from the cluster in the SOM grid. The new cluster means are the predicted values from this regression.
|