Launch the K Means Cluster Platform
Launch the K Means Cluster platform by selecting Analyze > Clustering > K Means Cluster.
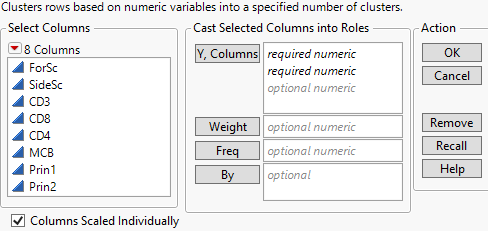
Figure 13.6 K Means Cluster Launch Window
For more information about the options in the Select Columns red triangle menu, see Column Filter Menu in Using JMP.
Y, Columns
The variables used for clustering observations.
Note: K-Means clustering supports only numeric columns.
Weight
A column whose numeric values assign a weight to each row in the analysis.
Freq
A column whose numeric values assign a frequency to each row in the analysis.
By
A column whose levels define separate analyses. For each level of the specified column, the corresponding rows are analyzed. The results are presented in separate reports. If more than one By variable is assigned, a separate analysis is produced for each possible combination of the levels of the By variables.
Launch Window Options
Columns Scaled Individually
Scales each column independently of the other columns. Use when variables do not share a common measurement scale, and you do not want one variable to dominate the clustering process. For example, one variable might have values that are between 0 and 1000, and another variable might have values between 0 and 10. In this situation, you can use the option so that the clustering process is not dominated by the first variable.
When you click OK, a Control Panel appears. See Iterative Clustering Control Panel.