Text Data Files
Text Data File preferences customize importing and exporting text files.
Figure 13.9 Text Data Files Preferences
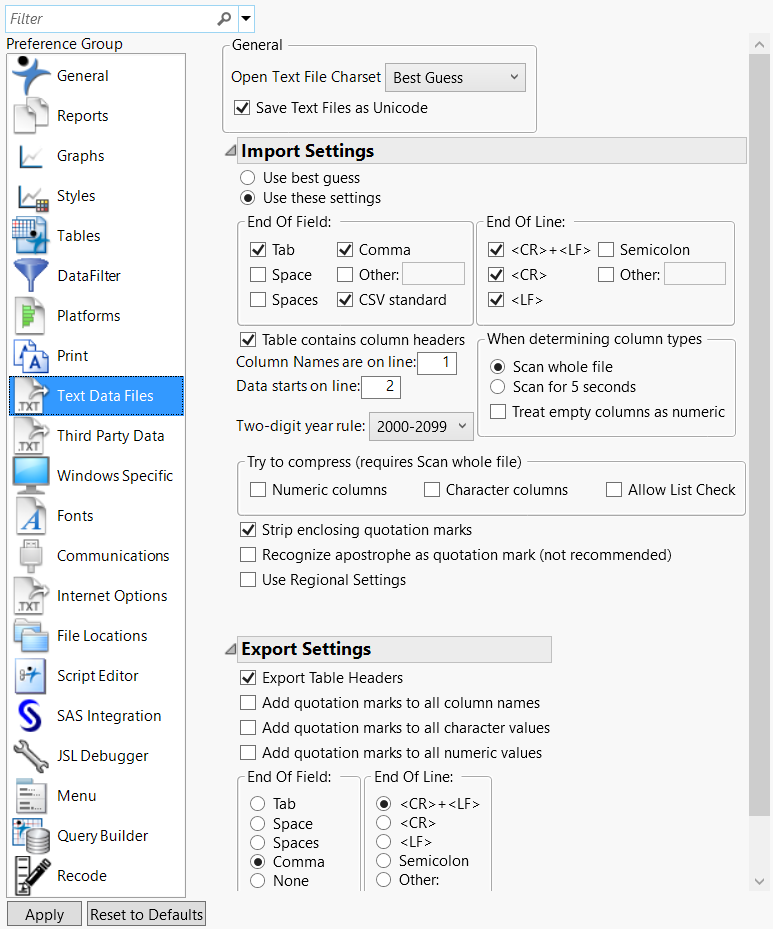
Preference | Description |
|---|---|
Open Text File Charset | Select one of the options from the menu to determine what character encoding JMP uses to open files. Best Guess is the default. Note that Windows-1252 is considered ANSII on some systems, and UTF-8-BOM is not supported. |
Save Text Files as Unicode | JMP uses the Unicode character set, which supports special characters such as é and ½. It saves files without special Unicode characters as plain text automatically. This option is selected by default. Clear this check box to save all your files as plain text. |
Import Settings | Select the strategy JMP uses to open text files. The default selection is Use these settings. In that case, you need to ensure that the settings reflect your text files. If you select Use Best Guess, JMP collects statistics in the text file on tabs, commas, blanks, and a few other characters and uses a rule-based system to decide what the file format might be. The rules try to make reasonable field widths and a reasonable number of fields per line. If your data format is too different from what the rules are designed to guess, JMP guesses incorrectly. In that case, either use the wizard or explicitly describe your data in these preference settings. |
End Of Field | Select one or more characters to use as the delimiter that signifies the end of a field when importing text data. Select the Other option and enter a character to specify a delimiter that is not listed. |
End Of Line | Select one or more characters to use as the delimiter that signifies the end of a line (row). Select the Other option and enter a character to specify a delimiter that is not listed. Note that if double-quotes are encountered when importing text data, the delimiter rules change to look for an end double-quote. Other text delimiters, including spaces, that are embedded within the quotes are ignored and treated as part of the text string. |
Table contains column headers | Select this option if your text file contains columns names. If you select this option, enter the line number where the column names are located in the field next to Column Names are on line. |
Column Names are on line | If you select the Table contains column headers option, enter the line number where the column names are located in this field. |
Data starts on line | Enter the line number where the data starts in your text file. |
When determining column types | Set how long JMP scans a text file to determine data types for the columns. Scan whole file is selected by default. Note that the Scan whole file option can cause importing a text file to be slow for large files. Consider selecting Scan for 5 seconds instead. When your text file contains columns of missing data, select Treat empty columns as numeric to import the columns as numeric rather than character. A period, Unicode dot, NaN, or a blank string are possible missing value indicators. This option is deselected by default. |
Two-digit year rule | Select the rule that you want to use to import dates that have two-digit years instead of four. For more information about these rules, see Two-digit year rule in the Import Your Data section. |
Try to compress | Select the options used for compressing text files. Available options are: • Numeric columns • Character columns • Allow List Check Note: This feature requires a scan of the entire file. |
Strip enclosing quotation marks | Select this option to remove quotation marks that enclose data in the text file. This option is selected by default. |
Recognize apostrophe as quotation mark | Select this option to treat apostrophes as quotation marks and omit them. This option is off by default. Note: This option is not recommended unless your data comes from a nonstandard source that places apostrophes around data fields rather than quotation marks. |
Use Regional Settings | Select this option to use the operating system’s regional settings when importing a text file. • If the option is deselected (the default setting), files that use a period for a decimal point and a comma for the value separator import correctly. • If the file uses a comma for a decimal point and some other value separator (and the regional settings use a comma for a decimal point), selecting this option imports the text correctly. You must specify the value separator in the Text Data Files import preferences. |
Preference | Description |
|---|---|
Export Table Headers | Select this option to include column names when you save data tables as text files. Selected by default. |
Add quotation marks to all column names | Select this option to insert quotation marks around column names. Used to export data to a program that has more stringent requirements than CSV. |
Add quotation marks to all character values | Select this option to insert quotation marks around character values. Used to export data to a program that has more stringent requirements than CSV. |
Add quotation marks to all numeric values | Select this option to insert quotation marks around numeric values. Used to export data to a program that has more stringent requirements than CSV. |
End Of Field | Select one or more characters to use as the delimiter signifying the end of a field when exporting text data. Select the Other option and enter a character to specify a delimiter that is not listed. |
End Of Line | Select one or more characters to use as the delimiter that signifies the end of a line (row). Select the Other option and enter a character to specify a delimiter that is not listed. |