Los gráficos de dispersión y otros gráficos parecidos ayudan a visualizar las relaciones entre variables. Una vez visualizadas estas relaciones, el paso siguiente es analizarlas para describirlas numéricamente. Esta descripción numérica de la relación entre variables se llama modelo. Es más importante saber que un modelo también predice el valor medio de una variable (Y) a partir del valor de otra variable (X). La variable X también se denomina predictor. Generalmente, este modelo se llama modelo de regresión.
En JMP, la plataforma Ajustar Y en función de X y la plataforma Ajuste del modelo crean modelos de regresión.
Nota: Aquí se describen solo las plataformas y las opciones básicas. Para leer explicaciones de todas las opciones de la plataforma, consulte Basic Analysis, Essential Graphing y la documentación que encontrará en Acerca de este capítulo.
Tabla 7.3 Tipos de relaciones muestra los cuatro tipos principales de relaciones.
|
La regresión logística es un tema avanzado. Consulte de Basic Analysis.
|
Este ejemplo utiliza la tabla de datos Companies.jmp, que contiene datos financieros de 32 empresas de los sectores farmacéutico e informático.
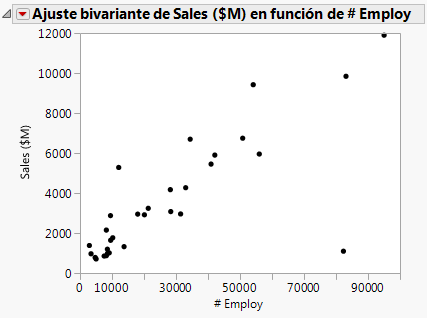
En primer lugar, cree un gráfico de dispersión para ver la relación entre el número de empleados y el valor de los ingresos por ventas. Este gráfico de dispersión se creó en el Crear el gráfico de dispersión en el capítulo Visualizar sus datos. Después de ocultar y excluir un valor atípico (una empresa con un número de empleados y ventas significativamente mayor), el gráfico de la Figura 7.12 Gráfico de dispersión de Sales ($M) frente a # Employ muestra el resultado.
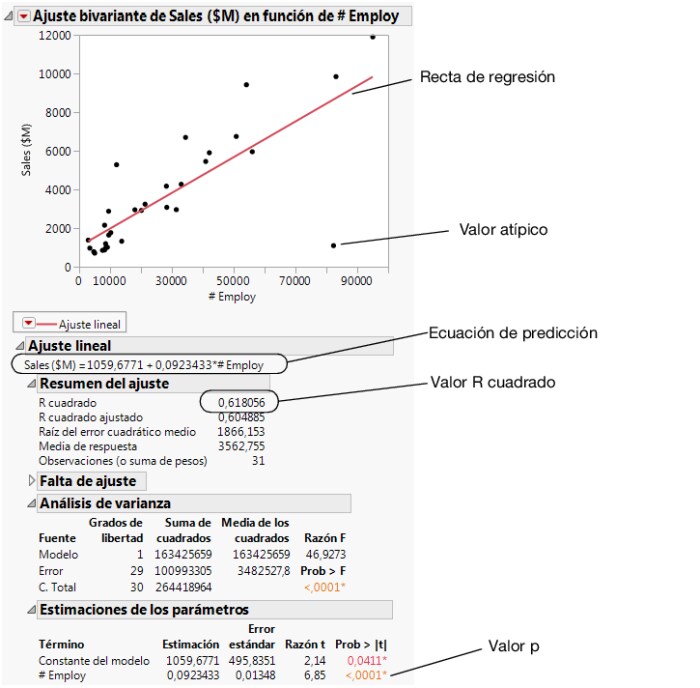
Para predecir los ingresos por ventas a partir del número de empleados, ajuste un modelo de regresión. Haga clic en el triángulo rojo junto a Ajuste bivariante y seleccione Ajustar línea. Se añade una recta de regresión en el gráfico de dispersión y aparecen informes en la ventana de resultados.
Figura 7.13 Recta de regresión
|
•
|
el valor p de <,0001
|
|
•
|
El valor p del término del modelo #Employ es pequeño. Esto sostiene que, al nivel de significación 0,05, el coeficiente de #Employ no sea cero. Por consiguiente, al incluir el número de empleados en el modelo de predicción mejora significativamente la capacidad de predecir el volumen medio de ventas con respecto a un modelo sin el número de empleados.
|
|
2.
|
|
3.
|
Figura 7.14 Comparación de los modelos
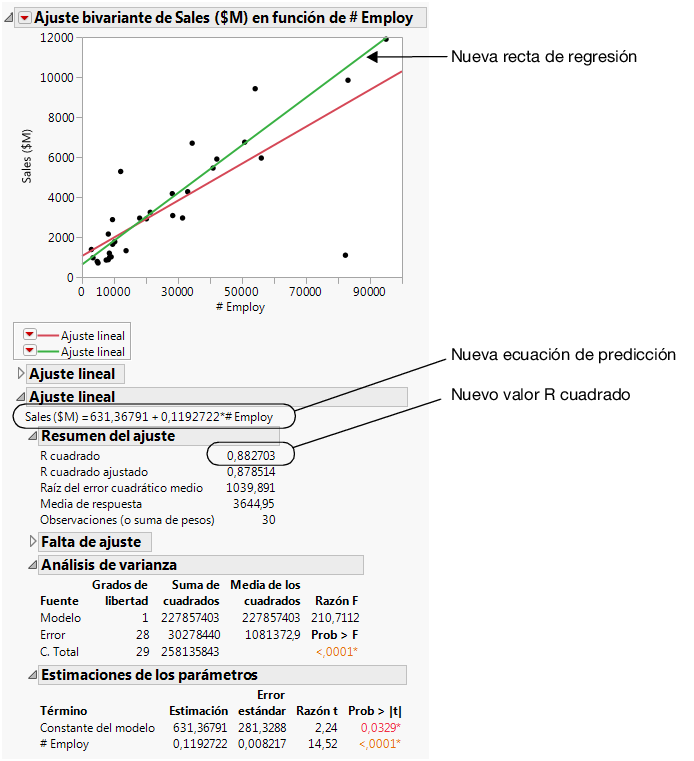
Usando los resultados de la Figura 7.14 Comparación de los modelos, el analista de datos puede sacar las conclusiones siguientes:
Este ejemplo utiliza la tabla de datos Companies.jmp, que contiene datos financieros de 32 empresas de los sectores farmacéutico e informático.
|
1.
|
|
2.
|
Si todavía tiene la tabla de la muestra de datos Companies.jmp abierta, es posible que tenga filas excluidas u ocultas. Para devolver las filas al estado predeterminado (todas las filas incluidas y ninguna oculta), seleccione Filas > Borrar estados de fila.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Haga clic en Aceptar.
|
Figura 7.15 Beneficios por tipo de empresa
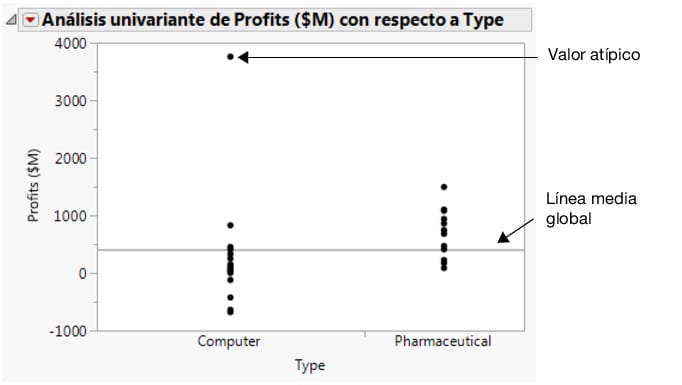
|
2.
|
Seleccione Filas > Excluir/Anular la exclusión. El punto de datos deja de incluirse en los cálculos.
|
|
3.
|
|
4.
|
Para volver a crear el gráfico sin el valor atípico, haga clic en Análisis univariante de Profits ($M) por Type y seleccione Rehacer > Rehacer análisis. La ventana del gráfico de dispersión original se puede cerrar.
|
Figura 7.16 Gráfico actualizado
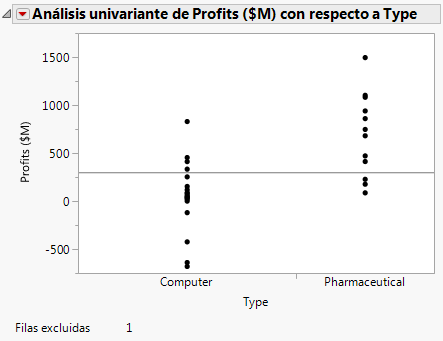
|
–
|
Opciones de visualización > Líneas de la media. Esta opción agrega las líneas de la media al gráfico de dispersión.
|
|
–
|
Medias y desviaciones estándar. Esta opción muestra un informe que contiene las medias y las desviaciones estándar.
|
Figura 7.17 Líneas de la media e informe
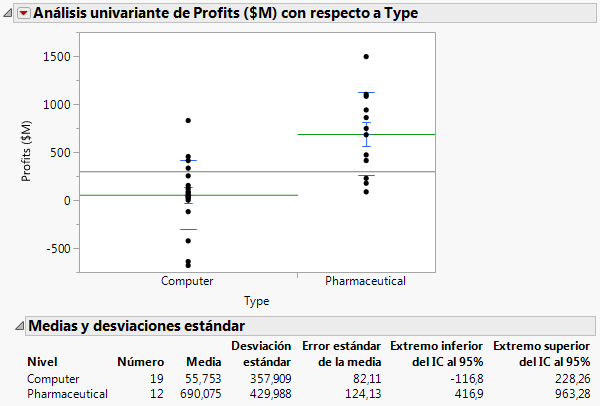
Para resolver estas preguntas, realicemos una prueba t para dos muestras. Una prueba t permite usar datos de una muestra para inferir acerca de la población mayor.
Para realizar la prueba t, haga clic en el triángulo rojo junto a Análisis univariante y seleccione Medias/ANOVA/t combinada.
Figura 7.18 Resultados de la prueba t

El valor p de 0,0001 es menor que el nivel de significación de 0,05, lo cual indica que hay significación estadística. Por consiguiente, el analista financiero puede concluir que la diferencia de beneficios medios de la muestra de datos no solo se debe al azar. Esto significa que en la población mayor, los beneficios medios de las empresas farmacéuticas son distintos de los beneficios medios de las empresas de informática.
Utilice los límites del intervalo de confianza para determinar cuál es la diferencia entre los beneficios de ambos tipos de empresas. Veamos los valores de Diferencia del límite de control superior y Diferencia del límite de control inferior en la Figura 7.18 Resultados de la prueba t. El analista financiero concluye que el beneficio medio de las empresas farmacéuticas es entre 343 millones de USD y 926 millones de USD mayor que el beneficio medio de las empresas de informática.
Si dispone de variables categóricas X e Y, puede comparar las proporciones de los niveles de la variable Y respecto a los niveles de la variable X.
Este ejemplo sigue utilizando la tabla de datos Companies.jmp. En Comparar medias para una variable, un analista financiero determinó que las empresas farmacéuticas tienen, en promedio, beneficios superiores que las empresas de informática.
|
1.
|
|
2.
|
Si todavía tiene el archivo de datos Companies.jmp abierto del ejemplo anterior, es posible que tenga filas excluidas u ocultas. Para devolver las filas al estado predeterminado (todas las filas incluidas y ninguna oculta), seleccione Filas > Borrar estados de fila.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
Haga clic en Aceptar.
|
Figura 7.19 Tamaño de empresa frente a tipo de empresa
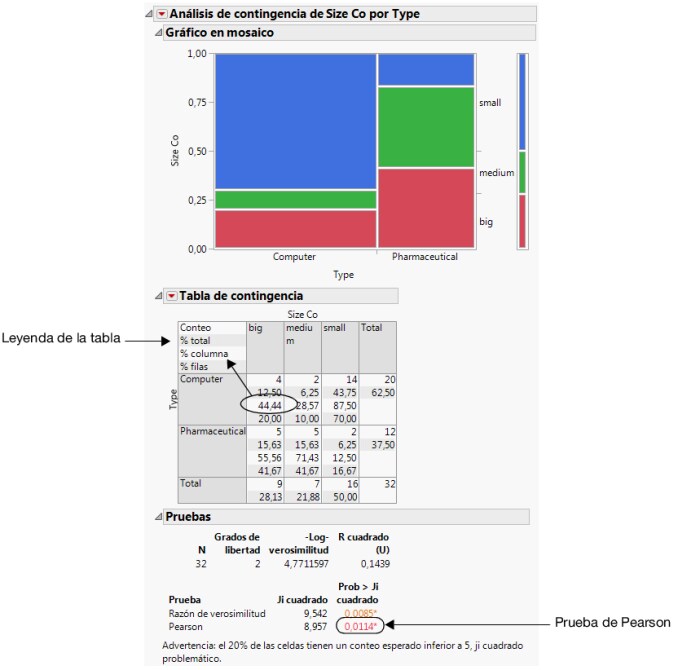
La Tabla de contingencia contiene información que no es aplicable a este ejemplo. Haga clic en el menú con triángulo rojo junto a Tabla de contingencia y deseleccione % total y % columna para quitar esa información. Figura 7.20 Tabla de contingencia actualizada muestra la tabla actualizada.
Figura 7.20 Tabla de contingencia actualizada
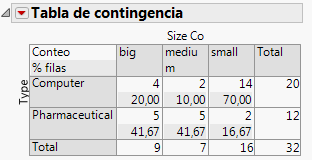
Para responder a esta pregunta, utilizamos el valor p de la prueba de Pearson del informe Pruebas (Tamaño de empresa frente a tipo de empresa). Puesto que el valor p de 0,011 es menor que el nivel de significación de 0,05, el analista financiero puede sacar estas conclusiones:
En la sección Comparar medias para una variable se comparaban las medias en distintos niveles de una variable categórica. Para comparar las medias entre los niveles de dos o más variables a la vez, utilice la técnica de Análisis de la varianza (o ANOVA).
|
•
|
Type (farmacéutica o de informática)
|
|
•
|
Size (pequeña, mediana o grande)
|
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
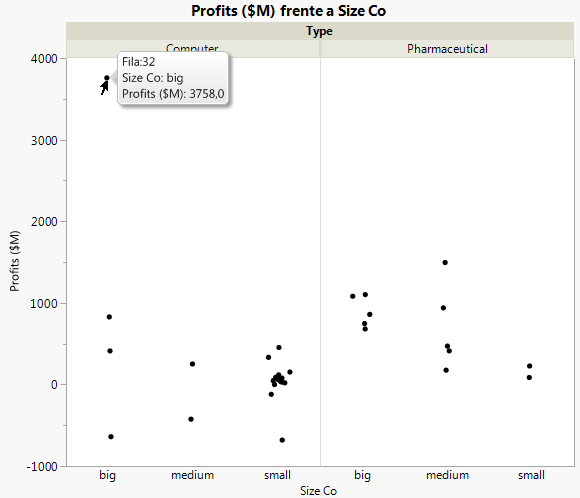
Figura 7.21 Gráfico de los beneficios de las empresas
|
6.
|
Seleccione el valor atípico y, a continuación, haga clic con el botón derecho y seleccione Filas > Exclusión de filas. El punto se quita y la escala del gráfico se actualiza automáticamente.
|
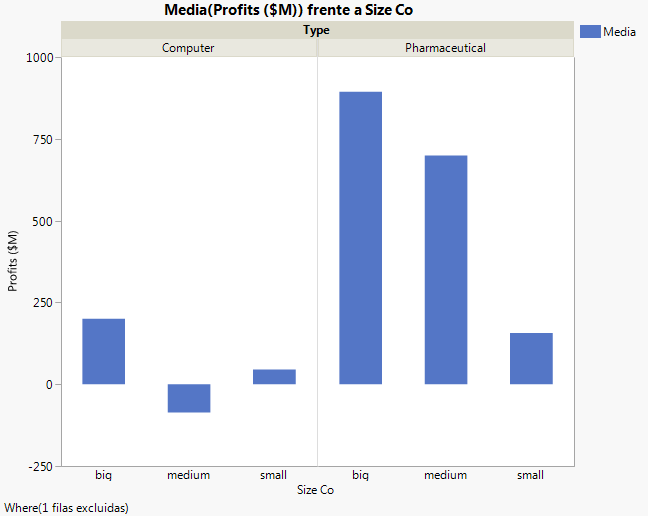
Figura 7.22 Gráfico después de quitar el valor atípico
|
1.
|
Vuelva a la tabla de la muestra de datos Companies.jmp con el punto de datos excluido. Consulte Descubrir la relación.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
|
6.
|
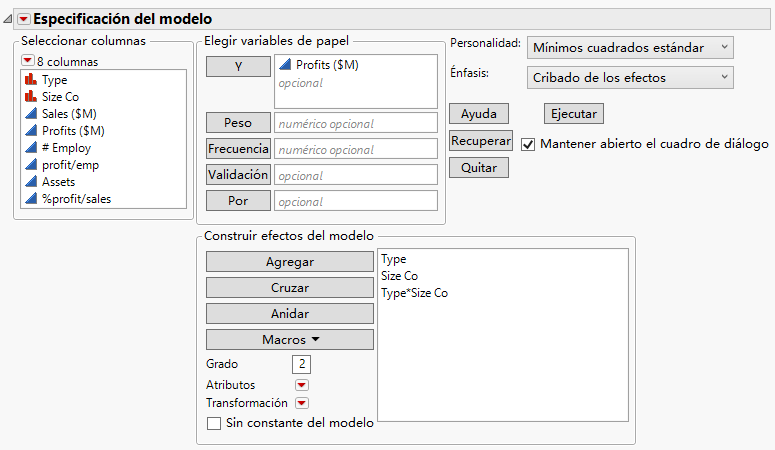
En el menú Énfasis, seleccione Cribado de los efectos.
|
|
7.
|
Seleccione la opción Mantener abierto el cuadro de diálogo.
|
Figura 7.23 Ventana Ajuste del modelo completada
|
8.
|
Haga clic en Ejecutar. La ventana de resultados muestra los resultados del modelo.
|
Para decidir si las diferencias entre beneficios son reales o se deben al azar, examine el informe Pruebas de los efectos.
Nota: Para conocer más detalles acerca de todos los resultados del Ajuste del modelo, consulte de Fitting Linear Models.
El informe Pruebas de los efectos (Figura 7.24 Informe Pruebas de los efectos) muestra los resultados de las pruebas estadísticas. Existe una prueba para cada efecto incluido en el modelo en la ventana Ajuste del modelo: Type, Size Co y Type*Size Co.
Figura 7.24 Informe Pruebas de los efectos
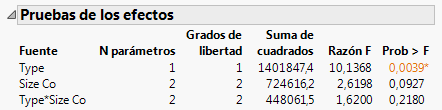
En primer lugar, veamos la prueba de la interacción del modelo: el efecto Type*Size Co. En la Figura 7.22 Gráfico después de quitar el valor atípico se observaba que las empresas farmacéuticas parecían tener beneficios distintos en función del tamaño de la empresa. No obstante, la prueba del efecto indica que no hay interacción entre el tipo y el tamaño en cuanto a beneficios se refiere. El valor p de 0,218 es grande (mayor que el nivel de significación de 0,05). Por consiguiente, podemos quitar ese efecto del modelo y volver a ejecutarlo.
|
2.
|
|
3.
|
Haga clic en Ejecutar.
|
Figura 7.25 Informe Pruebas de los efectos actualizado
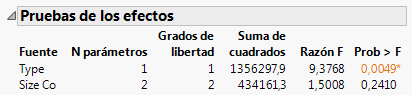
El valor p del efecto Size Co es grande, lo cual indica que no hay diferencias debidas al tamaño en la población general. El valor p del efecto Type es pequeño, lo cual indica que las diferencias observadas en los datos entre las empresas de informática y las empresas farmacéuticas no se deben al azar.
En la sección Utilizar la regresión con un predictor se mostraba cómo se pueden construir modelos simples de regresión con un predictor y una variable de respuesta. La regresión múltiple predice la variable respuesta media utilizando dos o más predictores.
Este ejemplo utiliza la tabla de datos Candy Bars.jmp, que contiene información nutricional de barras de caramelo.
Utilice la regresión múltiple para realizar una predicción de la variable respuesta media utilizando estos tres predictores.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
|
5.
|
Haga clic en Aceptar.
|
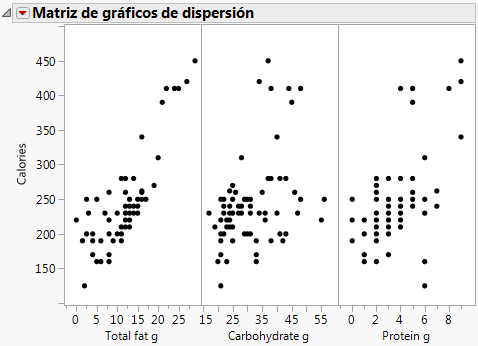
Siga utilizando la tabla de la muestra de datos Candy Bars.jmp.
|
1.
|
|
2.
|
|
3.
|
|
4.
|
Junto a Énfasis, seleccione Cribado de los efectos.
|
Figura 7.27 Ventana Ajuste del modelo
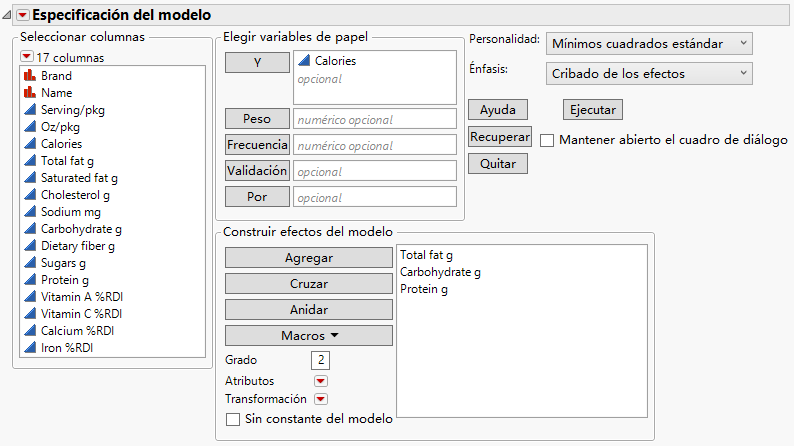
|
5.
|
Haga clic en Ejecutar.
|
Nota: Para conocer más detalles acerca de todos los resultados del modelo, consulte de Fitting Linear Models.
El gráfico Observados frente a predichos muestra las calorías reales frente a las predichas. Puesto que los valores predichos se acercan a los valores reales, los puntos del gráfico de dispersión quedan cerca de la línea roja (Figura 7.28 Gráfico Observados frente a predichos). Como se puede observar, los puntos están muy cerca de la línea, así que el modelo predice bien las calorías a partir de los factores elegidos.
Figura 7.28 Gráfico Observados frente a predichos
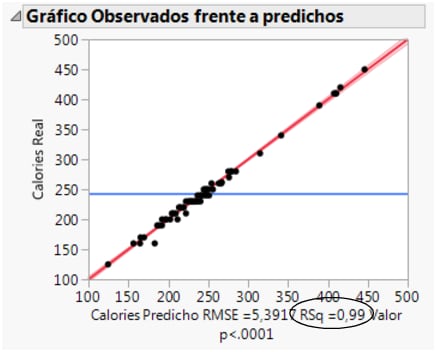
Otra medida de precisión del modelo es el valor R cuadrado, que aparece debajo del gráfico en la Figura 7.28 Gráfico Observados frente a predichos. El valor RSq mide el porcentaje de la variabilidad de las calorías explicada por el modelo. Un valor cerca de 1 significa que el modelo predice bien. En este ejemplo, el valor RSq es 0,99.
|
•
|
los valores p de cada parámetro
|
Figura 7.29 Informe Estimación de los parámetros
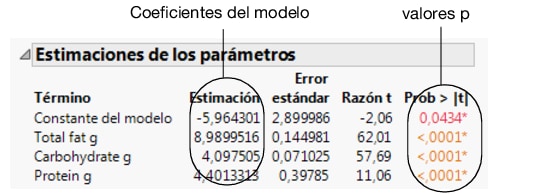
En este ejemplo, los valores p son muy pequeños (<0,0001). Esto indica que los tres efectos (grasa, carbohidratos y proteínas) contribuyen de forma significativa a la predicción de calorías.
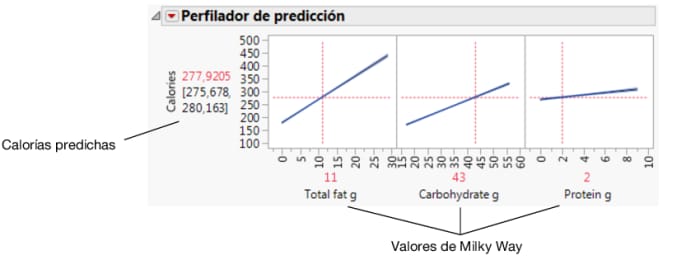
Mediante el Perfilador de predicción se puede estudiar cómo los cambios en los factores afectan a los valores predichos. Las líneas de perfil muestran la magnitud del cambio en las calorías a medida que cambia el factor. La línea de Total fat g es la más inclinada, lo cual significa que las variaciones en la grasa total tienen el efecto mayor sobre las calorías.
Figura 7.30 Perfilador de predicción
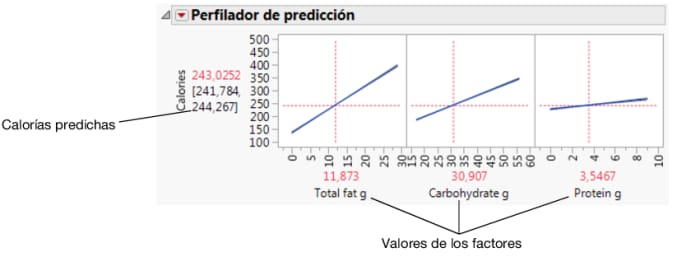
Figura 7.31 Valores de los factores para Milky Way