 「単純Bayes」の別例
「単純Bayes」の別例
住宅担保ローンに応募した5,960人の顧客の資産状況に関する履歴データがあります。各顧客は、「リスクが低い」(Good Risk)と「リスクが高い」(Bad Risk)に分類されています。ほとんどの説明変数に欠測値があります。未来の顧客のクレジットリスクを分類するためのモデルを作成してみましょう。
1. [ヘルプ]>[サンプルデータライブラリ]を選択し、「Equity.jmp」を開きます。
2. [分析]>[予測モデル]>[単純Bayes]を選択します。
3. 「BAD」を選択し、[Y, 目的変数]をクリックします。
説明変数として使えるかもしれない「DEBTINC」には、欠測値が多数あります。このような欠測値が多い変数を説明変数に含めたほうが予測能力が上がる場合もありますが、単純Bayes法は多数の欠測値をうまく処理することができないため、ここでは「DEBTINC」をモデルに含めないことにします。
4. 「LOAN」から「CLNO」までを選択し、[X, 説明変数]をクリックします。
5. 「検証」列を選択し、[検証]ボタンをクリックします。
6. [OK]をクリックします。
図8.8 「BAD」の「単純Bayes」レポート
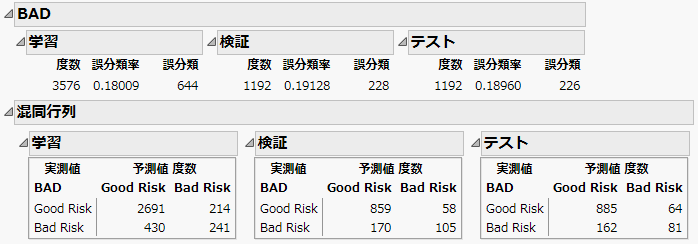
学習セット、検証セット、テストセットの誤分類率は18~19%です。各セットの混同行列を見ると、誤分類の多くは「Bad Risk」(リスクが高い)の顧客を誤って「Good Risk」(リスクが低い)に分類したことに起因しています。
顧客の資産状況に基づいて、その顧客のリスクが高いかどうかを求めてみましょう。
7. 「単純Bayes」の赤い三角ボタンをクリックし、[確率の計算式を保存]を選択します。
データテーブルには、3種類の列が追加されます。
– 「単純 スコア」の3つの列には、「Good Risk」と「Bad Risk」のスコア、および、それらの和が含まれます。
– 「単純 確率」の2つの列には、「Good Risk」と「Bad Risk」の事後確率を求める計算式が含まれます。
– 「単純 予測式 BAD」列には、事後確率が最大となっているクラスに割り当てる計算式が保存されています。
これらの計算式は、新しい顧客のスコアを計算するときにも使用できます。計算式列の詳細については、確率の計算式を参照してください。