連続尺度の応答変数を用いた例
この例では、「パーティション」プラットフォームを使用して、糖尿病患者における1年間の症状進行を予測するディシジョンツリーを構築します。この症状進行は、数値で測定されています。
1. [ヘルプ]>[サンプルデータライブラリ]を選択し、「Diabetes.jmp」を開きます。
2. [分析]>[予測モデル]>[パーティション]を選択します。
3. 「Y」を選択し、[Y, 目的変数]をクリックします。
4. 「年齢」から「グルコース」までを選択し、[X, 説明変数]をクリックします。
5. お使いのJMPに基づいて検証手順を選択します。
– JMP Proの場合は、「検証」を選択し、[検証]をクリックします。
– JMPの場合は、「検証セットの割合」に「0.3」と入力します。
注: 「検証セットの割合」を使用した場合、検証セットが無作為に選択されるために、本節で示すものと結果が異なってきます。
図4.20 指定が完了した起動ウィンドウ、「検証セットの割合」を「0.3」に指定
6. [OK]をクリックします。
7. プラットフォームのレポートウィンドウで、[分岐]を1回クリックして分岐を実行します。
図4.21 ディシジョンツリーを隠した状態の最初の分岐後のレポート
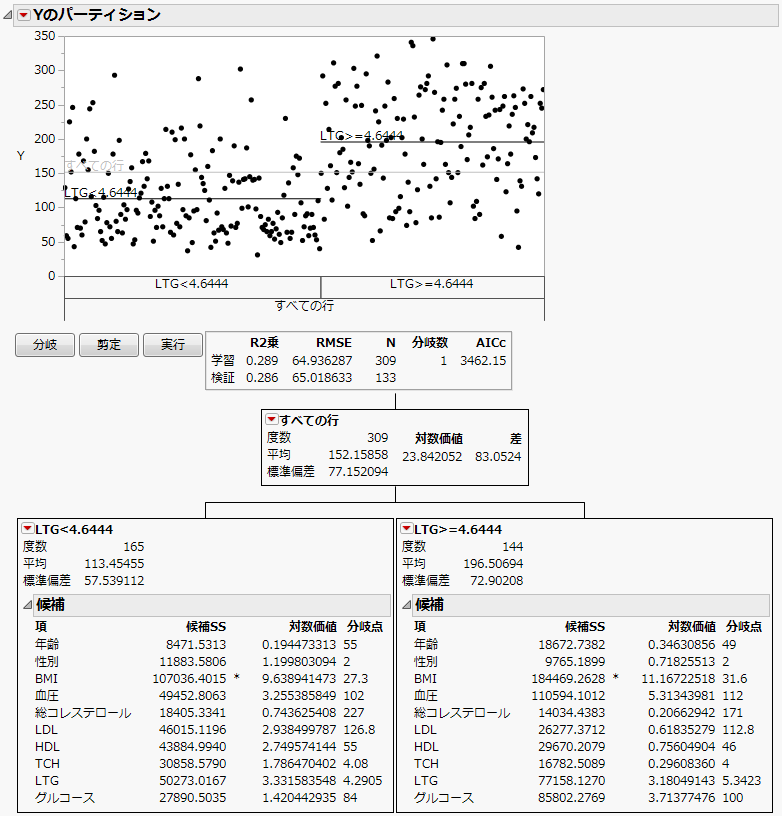
学習セットには309行がありますが、それらが2つに分割されます。
– 左の葉は「LTG」が4.6444未満のデータで、165行あります。
– 右の葉は「LTG」が4.6444以上のデータで、144行あります。
左の葉も右の葉も、次の分岐は「BMI」で行われます。右の葉の「BMI」の「候補SS」は、左の葉の「BMI」の「候補SS」より高くなっています。したがって、次の分岐は右の葉で行われます。
8. [実行]をクリックして自動分岐を使用します。
図4.22 検証を使った自動分岐後のレポート
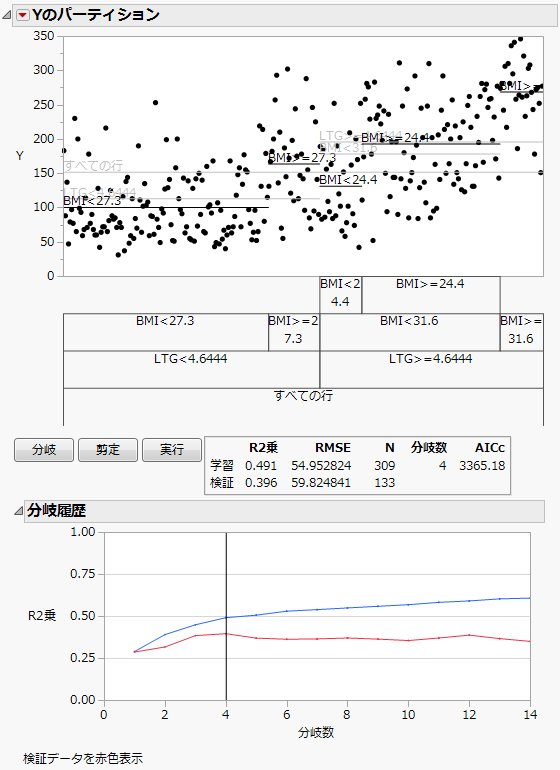
最終的なツリーでは、4回の分岐が行われています。「分岐履歴」プロットを見ると、その4回の分岐のあとには、検証セットにおけるR2乗値が改善していません。検証セットのR2乗値は0.39ですので、このモデルでは症状進行を精確には予測できないようです。また、先頭のプロットからも、各ノードにおいて応答変数のばらつきが大きいことから、応答変数を精確に予測できていないことが分かります。