 「モデルの比較」の例
「モデルの比較」の例
この節では、「モデルの比較」プラットフォームの使用例を紹介します。使用するデータは、住宅価格のデータです。各地域における住宅価格の中央値を、その地域の属性から予測するモデルを作成します。回帰モデルとブートストラップ森を比較します。
まず、[ヘルプ]>[サンプルデータライブラリ]を選択し、「Boston Housing.jmp」を開いてください。
検証列の作成
1. [分析]>[予測モデル]>[検証列の作成]を選択します。
2. 起動ウィンドウでは列を選択しないでください。
これにより、単純無作為抽出による1つの検証列が作成されます。
3. [OK]をクリックします。
4. 「新しい列の名前」の横のボックスに「検証列の作成」と入力します。
5. 「乱数シード値」の横のボックスに「1234」と入力します。
6. [実行]をクリックします。
新しい検証列が作成されます。0が割り当てられた行は学習セットとして使われます。一方、1が割り当てられた行は検証セットとして使われます。
回帰モデルを作成し、予測式を列に保存
1. [分析]>[モデルのあてはめ]を選択します。
2. 「持ち家の価格」を選択し、[Y]をクリックします。
3. 「犯罪率」から「低所得者」までを選択し、[追加]をクリックします。
4. 「検証列の作成」を選択し、[検証]をクリックします。
5. 「手法」リストから[ステップワイズ法]を選択します。
6. [実行]ボタンをクリックします。
7. 「停止ルール」リストから[閾値p値]を選択します。
8. [実行]ボタンをクリックします。
9. [モデルの実行]ボタンをクリックします。
図10.2 「モデルのあてはめ」レポート
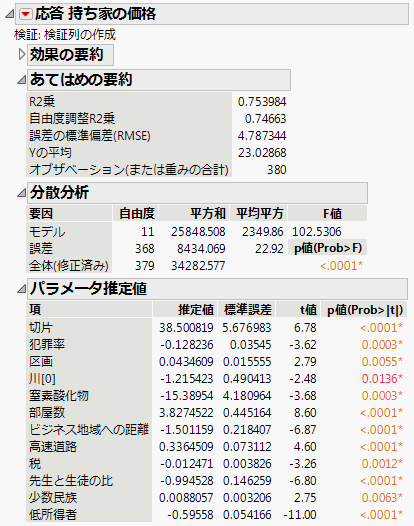
10. 予測式を列に保存するには、「応答」の赤い三角ボタンをクリックし、[列の保存]>[予測式]を選択します。
ブートストラップ森モデルを作成し、予測式を列に保存
1. [分析]>[予測モデル]>[ブートストラップ森]を選択します。
2. 「持ち家の価格」を選択し、[Y, 目的変数]をクリックします。
3. 「犯罪率」から「低所得者」までを選択し、[X, 説明変数]をクリックします。
4. 「検証列の作成」を選択し、[検証]をクリックします。
5. [OK]をクリックします。
6. [早期打ち切り]チェックボックスをオンにします。
7. [項数に対する複数のあてはめ]チェックボックスをオンにします。
8. 「乱数シード値」の横のボックスに「617」と入力します。
9. [OK]をクリックします。
図10.3 ブートストラップ森のモデル
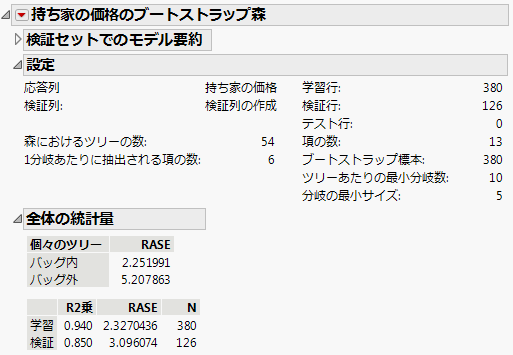
10. 予測式を列に保存するには、「ブートストラップ森」の赤い三角ボタンをクリックし、[列の保存]>[予測式の保存]を選択します。
モデルの比較
1. [分析]>[予測モデル]>[モデルの比較]を選択します。
2. 2つの予測式列を選択し、[Y, 予測子]をクリックします。
3. 「検証列の作成」を選択し、[グループ化]をクリックします。
ヒント: グループ化の列が選択されなかった場合、JMPはすべての説明変数に対して同じ検証列が使用されたときを認識し、それをグループ変数として追加するよう指示するメッセージを表示します。
4. [OK]をクリックします。
図10.4 「モデルの比較」レポート
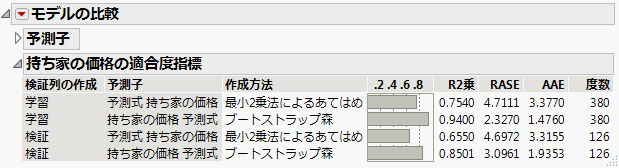
学習セットの行は、モデルの構築に使用されています。そのため、「検証の作成」=「学習」のR2乗は過度に大きくなっている可能性があります。学習セットのR2乗は、将来のデータに対する予測精度を正しく反映していません。この傾向は、特にブートストラップ森に対して言えます。
「検証の作成」=「学習」の統計量を使用してモデルを比較してください。ブートストラップ森の方が回帰モデルより、R2乗値が大きくなっています。
5. [モデルの比較]の赤い三角をクリックし、[プロファイル]を選択します。
図10.5 すべてのモデルの予測プロファイル
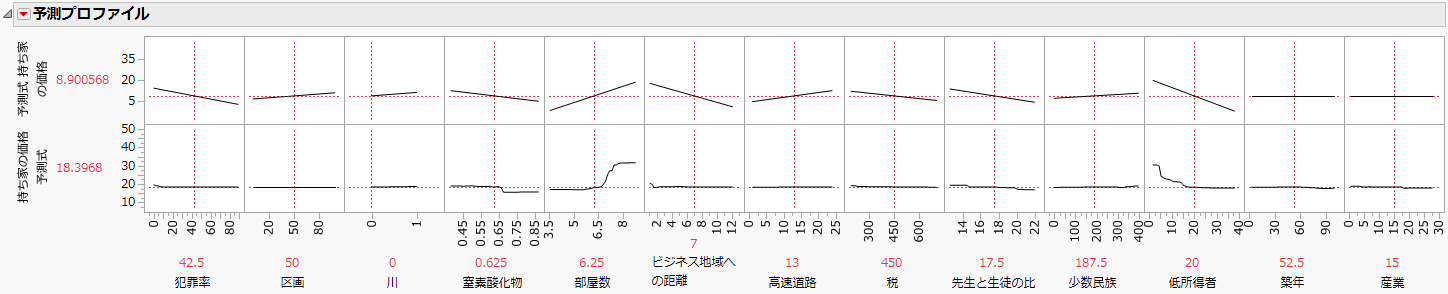
予測プロファイルを使用すると、異なるモデルの各因子の影響を比較できます。プロファイルは、この例で回帰モデルとパーティションモデルを比較したように、異なる種類のモデルを比較するのに役立ちます。
• 『基本的な回帰モデル』のモデルの指定を参照してください。
• パーティション