利益行列と決定行列の例
この例では、肝臓がんを患う患者の調査を見てみましょう。あなたは、さまざまな測定値やマーカーに基づき、病気の重症度(HighまたはLow)のいずれかに患者を分類したいとします。患者を分類する上で考えられる間違いには2つあります。つまり、重症度がHighの患者をLowグループに分類してしまうこと、および重症度がLowの患者をHighグループに分類してしまうことです。臨床上、重症度が実際にはHighである患者をLowに分類してしまうことはコストが大きいと考えられます。なぜなら、その患者は必要な治療を受けることができない可能性があるからです。それに比べ、重症度が実際にはLowの患者をHighに分類してしまっても、それほどコストは大きくないと考えられます。その患者は必要とされる以上の治療を受けるかもしれませんが、それが大きな問題になることはないと考えられます。
次の例では、肝臓がんに関して利益行列を定義します。分析すると、「決定行列」レポートを得ます。この「決定行列」レポートを見ることで、定義した利益行列のコストに応じた分類を評価できます。
1. [ヘルプ]>[サンプルデータライブラリ]を選択し、「Liver Cancer.jmp」を開きます。
2. [分析]>[予測モデル]>[パーティション]を選択します。
3. 「重症」を選択し、[Y, 目的変数]をクリックします。
4. 「BMI」から「黄疸」までを選択し、[X, 説明変数]をクリックします。
5. お使いのJMPに基づいて検証手順を選択します。
– JMP Proの場合は、「検証」を選択し、[検証]をクリックします。
– JMPの場合は、「検証セットの割合」に「0.3」と入力します。
注: 「検証セットの割合」を使用した場合、検証セットが無作為に選択されるために、ここで示すものと結果が異なってきます。
図4.25 指定が完了した起動ウィンドウ、「検証セットの割合」を「0.3」に指定
6. [OK]をクリックします。
7. Shiftキーを押しながら[分岐]をクリックします。
8. 「分岐数を入力」に「10」と入力し、[OK]をクリックします。
プロットの下のパネルで「分岐数」が10になっていることを確認してください。
9. 「重症のパーティション」の横にある赤い三角ボタンをクリックし、[利益行列の指定]を選択します。
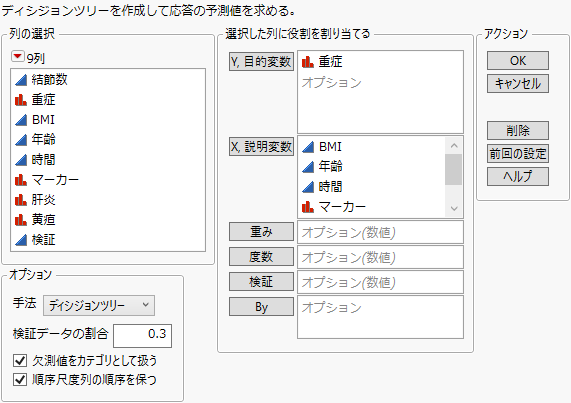
10. 入力内容を次のように変更します。
– High行High列のボックスに「1」と入力します。
– High行Low列のボックスに「-5」と入力します。
– Low行High列のボックスに「-3」と入力します。
– Low行Low列のボックスに「1」と入力します。
図4.26 指定後の利益行列
ヒント: この利益行列は今後の分析で使用できるように列プロパティとして保存できます。その場合は、利益行列ウィンドウの下部にある[列プロパティとして保存する]チェックボックスをオンにします。
次の点を念頭に置いてください。
– 値1はいずれも、正しい決定を下したときの利益を反映しています。
– 値-3は、重症度が実際にはLowの患者をHighとして分類してしまった場合に、損失が正しい決定を下したときに得られる利益の3倍であることを意味します。
– 値-5は、重症度が実際にはHighの患者をLowとして分類してしまった場合に、損失が正しい決定を下したときに得られる利益の5倍であることを意味します。
11. [OK]をクリックします。
12. 「重症のパーティション」の横にある赤い三角ボタンをクリックし、[あてはめの詳細の表示]を選択します。
図4.27 「混同行列」レポートと「決定行列」レポート
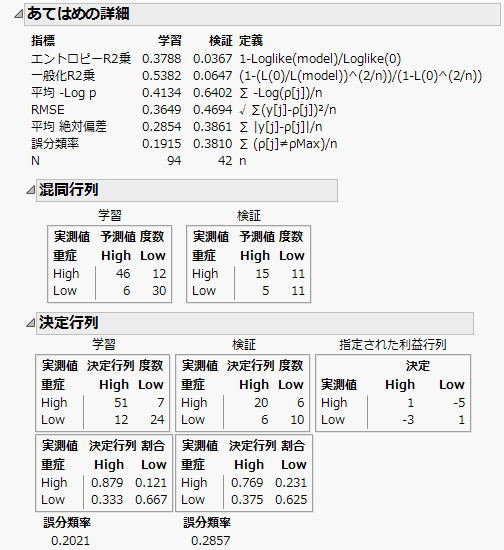
「あてはめの詳細」レポートの指標リストの下には「混同行列」レポートと「決定行列」レポートが表示されます。「混同行列」レポートと「決定行列」レポートの混同行列とでは、表示されている数値が異なることに注意してください。これは、利益行列に基づく分類が、何も重みづけないで行われた分類と異なるからです。
検証セットの混同行列には、予測確率のみに基づく分類が示されています。これによると、実際には重症度がHighの患者のうち11人はLowに分類され、実際には重症度がLowの患者のうち5人はHighに分類されることになります。
「決定行列」レポートでは、利益行列の重みが考慮されています。これらの重みを使用することにより、実際には重症度がHighの患者のうちLowに分類されるのは6人だけになります。その代り、実際には重要度がLowの患者のうち6人が誤ってHighの重症度グループに分類されてしまいます(1人多くなる)。
13. 「重症のパーティション」の赤い三角ボタンをクリックし、[列の保存]>[予測式の保存]を選択します。
8個の列がデータテーブルに追加されます。
ヒント: データテーブルにすばやく戻るには、(Windowsの場合)レポートウィンドウの右下隅にある[データの表示]アイコン![]() か、(macOSの場合)ツールバーメニューの[データテーブルの表示]アイコンをクリックします。
か、(macOSの場合)ツールバーメニューの[データテーブルの表示]アイコンをクリックします。
– 最初の3列は、予測確率に関するものです。このうち「最尤 重症」列は、最も予測確率の高い水準に分類しています。「混同行列」レポートの度数は、この結果に基づいています。予測確率は、「確率(重症y==High)」列と「確率(重症==Low)」列に含まれています。
– 最後の5列は、指定した利益行列に基づくものです。「利益が最大となる重症の予測値」列には利益行列に基づく決定が含まれています。そこでは、利益が最大となる水準に各患者が分類されています。利益は「Highの利益」列と「Lowの利益」列に含まれています。