하나의 예측 변수가 있는 회귀 사용 섹션에서는 하나의 예측 변수와 하나의 반응 변수로 구성된 단순 회귀 모형을 작성하는 방법을 소개했습니다. 다중 회귀는 둘 이상의 예측 변수를 사용하여 평균 반응 변수를 예측합니다.
이 예에서는 초코바의 영양 정보가 포함된 Candy Bars.jmp 데이터 테이블을 사용합니다.
|
•
|
|
•
|
|
•
|
다중 회귀를 사용하여 이 세 가지 예측 변수를 통해 평균 반응 변수를 예측합니다.
|
1.
|
도움말 > 샘플 데이터 라이브러리를 선택하고 Candy Bars.jmp를 엽니다.
|
|
2.
|
그래프 > 산점도 행렬을 선택합니다.
|
|
3.
|
Calories를 선택하고 Y, 열을 클릭합니다.
|
|
4.
|
|
5.
|
확인을 클릭합니다.
|
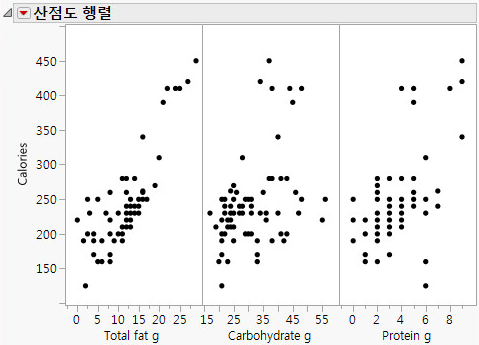
그림 5.26 산점도 행렬 결과
Candy Bars.jmp 샘플 데이터 테이블을 계속 사용합니다.
|
1.
|
분석 > 모형 적합을 선택합니다.
|
|
2.
|
Calories를 선택하고 Y를 클릭합니다.
|
|
3.
|
|
4.
|
강조 옆에서 효과 선별을 선택합니다.
|
그림 5.27 모형 적합 창
|
5.
|
실행을 클릭합니다.
|
실제값 대 예측값 그림은 실제 칼로리와 예측된 칼로리를 보여 줍니다. 예측값이 실제값에 더 가까워지면 산점도의 점은 빨간색 선으로 더 몰려듭니다. 실제값 대 예측값 그림을 참조하십시오. 점이 모두 선에 매우 가깝기 때문에 모형이 선택한 요인을 기반으로 칼로리를 정확하게 예측한다는 것을 알 수 있습니다.
그림 5.28 실제값 대 예측값 그림
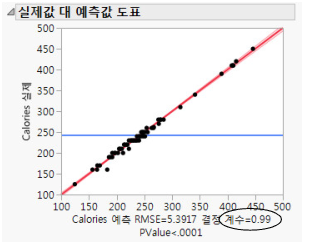
모형 정확도의 또 다른 척도는 R² 값입니다. 이 값은 실제값 대 예측값 그림의 그림 아래에 나타납니다. R² 값은 모형에 의해 설명된 대로 칼로리의 변동률을 측정합니다. 1에 가까운 값은 모형이 정확하게 예측한다는 것을 의미합니다. 이 예에서 R² 값은 0.99입니다.
모수 추정치 해석
|
•
|
그림 5.29 모수 추정치 보고서
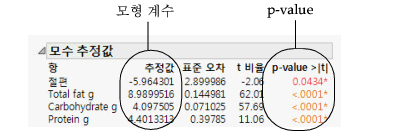
|
•
|
|
•
|
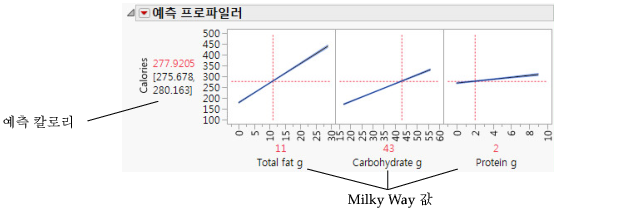
예측 프로파일러를 사용하여 요인의 변화가 예측값에 어떻게 영향을 미치는지 확인할 수 있습니다. 프로파일 선은 요인이 바뀜에 따라 변화되는 칼로리 크기를 보여 줍니다. Total fat g의 선이 가장 가파르며, 이는 총 지방의 변화가 칼로리에 가장 큰 영향을 미친다는 것을 의미합니다.
그림 5.30 예측 프로파일러
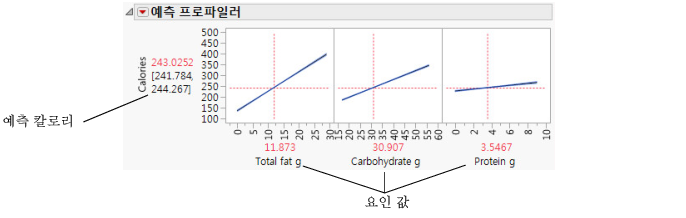
그림 5.31 Milky Way의 요인 값