이 예에서는 116가지 자동차 모델에 대한 정보가 들어 있는 Car Physical Data.jmp 데이터 테이블을 사용합니다.
|
1.
|
도움말 > 샘플 데이터 라이브러리를 선택하고 Car Physical Data.jmp를 엽니다.
|
|
2.
|
분석 > 분포를 선택합니다.
|
|
3.
|
Weight를 선택하고 Y, 열을 클릭합니다.
|
|
4.
|
확인을 클릭합니다.
|
|
5.
|
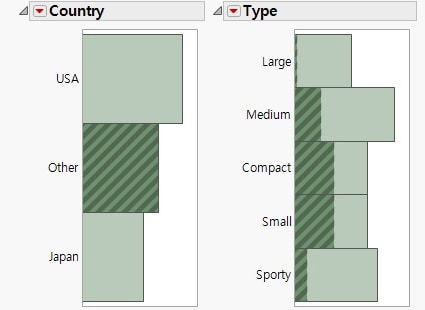
그림 5.7 Weight 분포
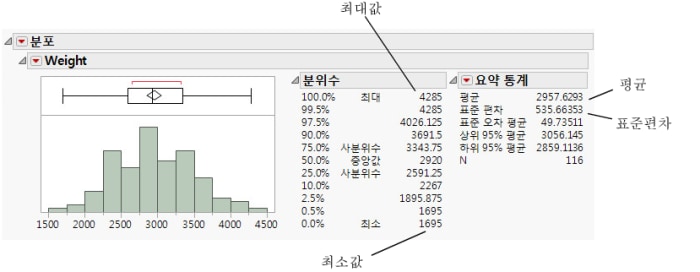
다른 조사 결과에 따라, 철도 회사는 평균 3,000파운드를 운송하는 것이 가장 효율적이라고 판단했습니다. 이제 계획 전문가는 운송할 수 있는 일반적인 자동차 모집단의 평균 자동차 중량이 3,000파운드인지 알아내야 합니다. t-검정을 통해 이 모집단 표본을 바탕으로 보다 광범위한 모집단에 대한 추론을 이끌어 내야 합니다.
|
1.
|
"Weight"의 빨간색 삼각형을 클릭하고 평균 검정을 선택합니다.
|
|
3.
|
확인을 클릭합니다.
|
그림 5.8 평균 검정 결과
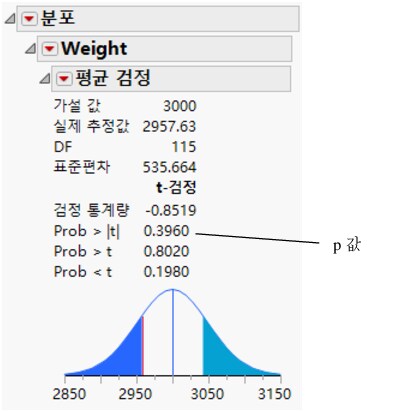
t-검정의 기본 결과는 p 값입니다. 이 예에서 p 값은 0.396이고 분석가는 0.05의 유의 수준을 사용합니다. 0.396은 0.05보다 크기 때문에 더 광범위한 모집단에서 자동차 모델의 평균 중량이 3,000파운드와 유의하게 다르다는 결론을 내릴 수는 없습니다. p 값이 유의 수준보다 낮았다면 계획 전문가는 더 광범위한 모집단의 평균 자동차 중량이 3,000파운드와 유의하게 다르다는 결론을 내렸을 것입니다.
자세한 내용은 연속형 변수의 분포의 시나리오에서 확인하십시오.
|
1.
|
도움말 > 샘플 데이터 라이브러리를 선택하고 Car Physical Data.jmp를 엽니다.
|
|
2.
|
분석 > 분포를 선택합니다.
|
|
3.
|
|
4.
|
확인을 클릭합니다.
|
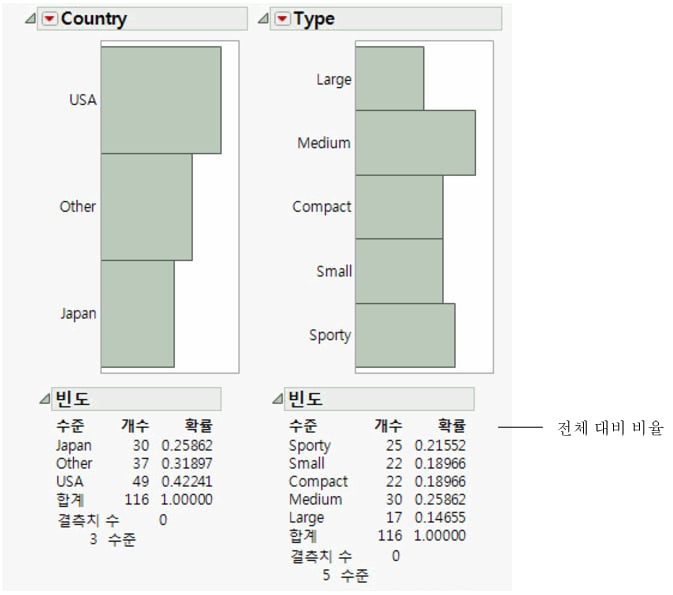
보고서 창에는 Country 및 Type에 대한 막대 차트와 "빈도" 보고서가 있습니다. 막대 차트는 "빈도" 보고서에서 제공된 빈도 정보를 그래픽으로 나타낸 것입니다. "빈도" 보고서에는 다음 항목이 포함됩니다.
그림 5.10 일본 자동차
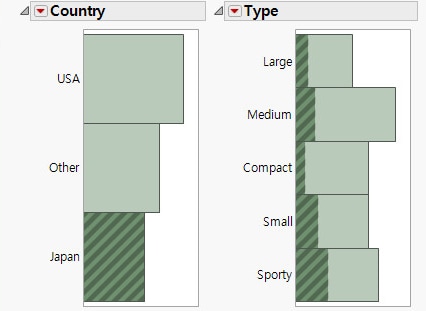
그림 5.11 기타 국가의 자동차